CMU15-445_3_Lecture_Note
# 03 - Database Storage I
Tags: #Database
# Outline
Different Layers of the whole system, One layer at a time, from bottom to top.
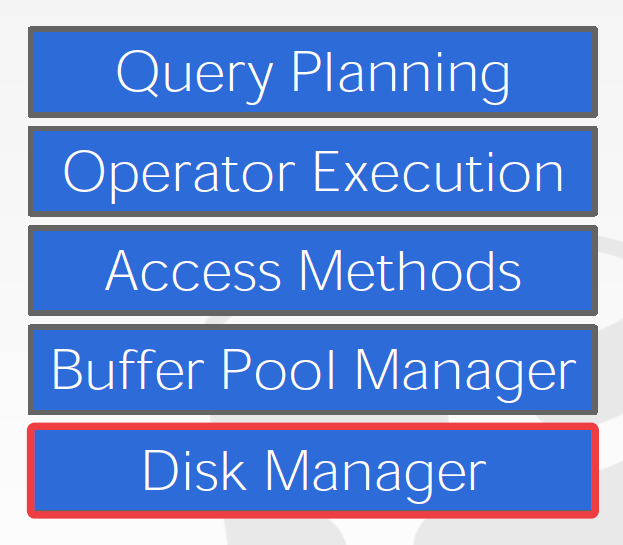
# Disk-Oriented Architecture
- Not in Memory
- Move data between non-volatile to volatile storage
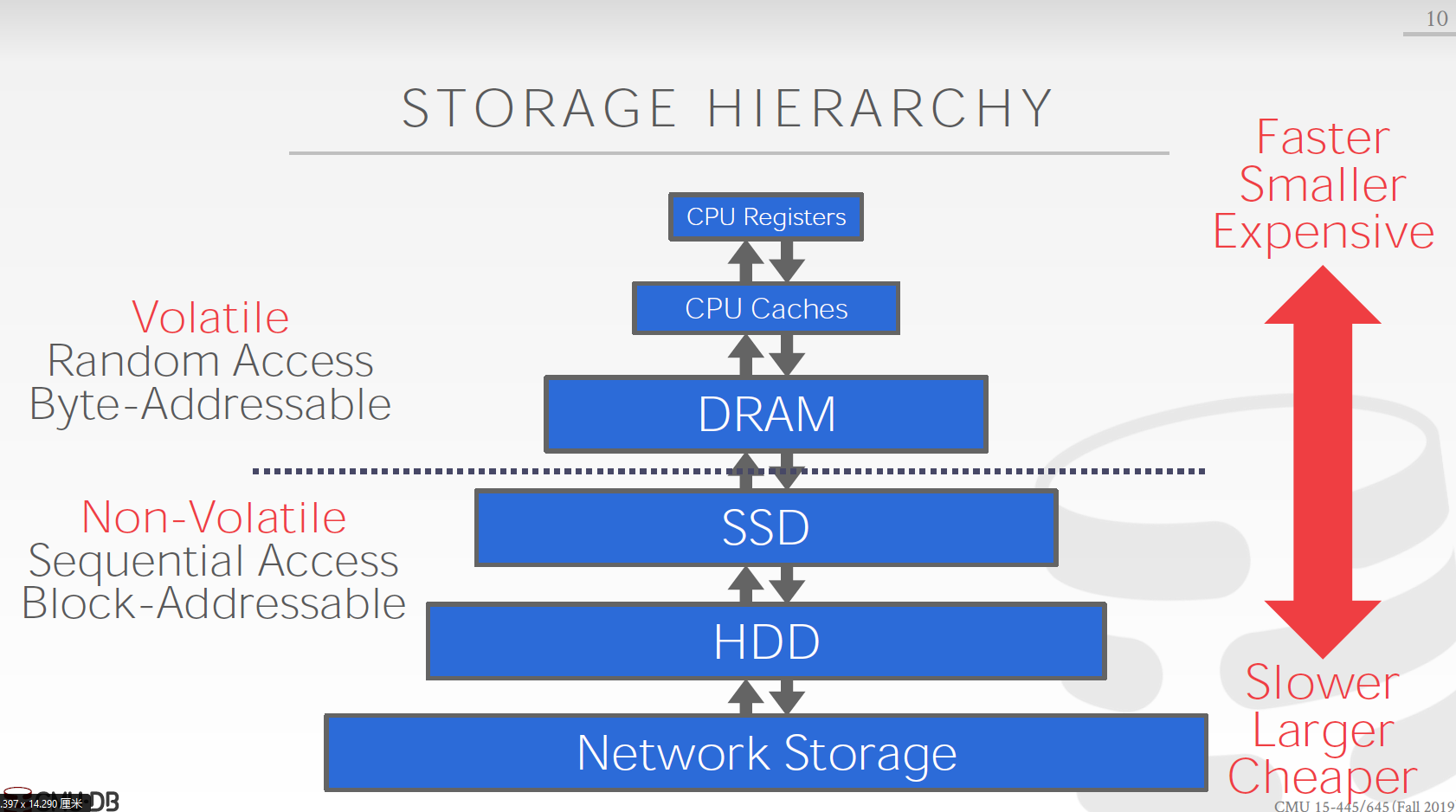
- 注意寻址方式也在变, 下面的是 Block-Addressable, 上面的是Byte-Addressable
- 下面的是Sequential的 上面的是Non-Sequential的
- 我们关心下面的三层和上面的第一层(这门课), 因为下面的实在是太慢了, 先考虑下面的
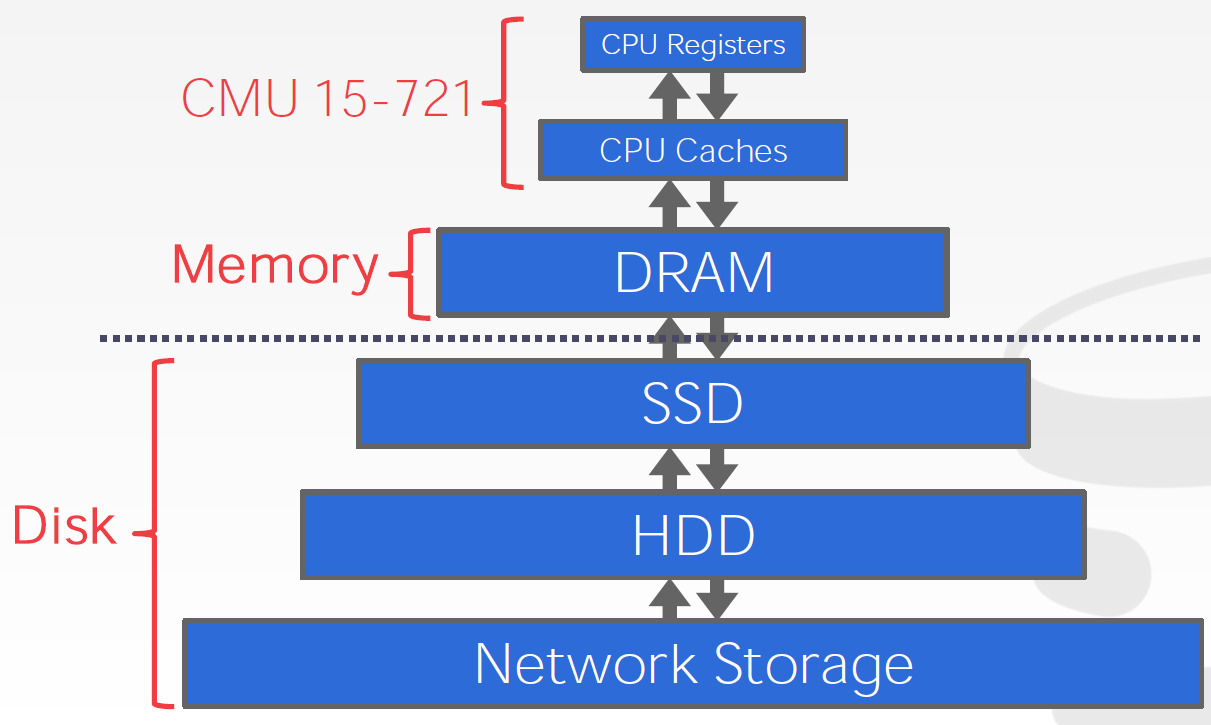
- First hand material: Non-volatile Memory
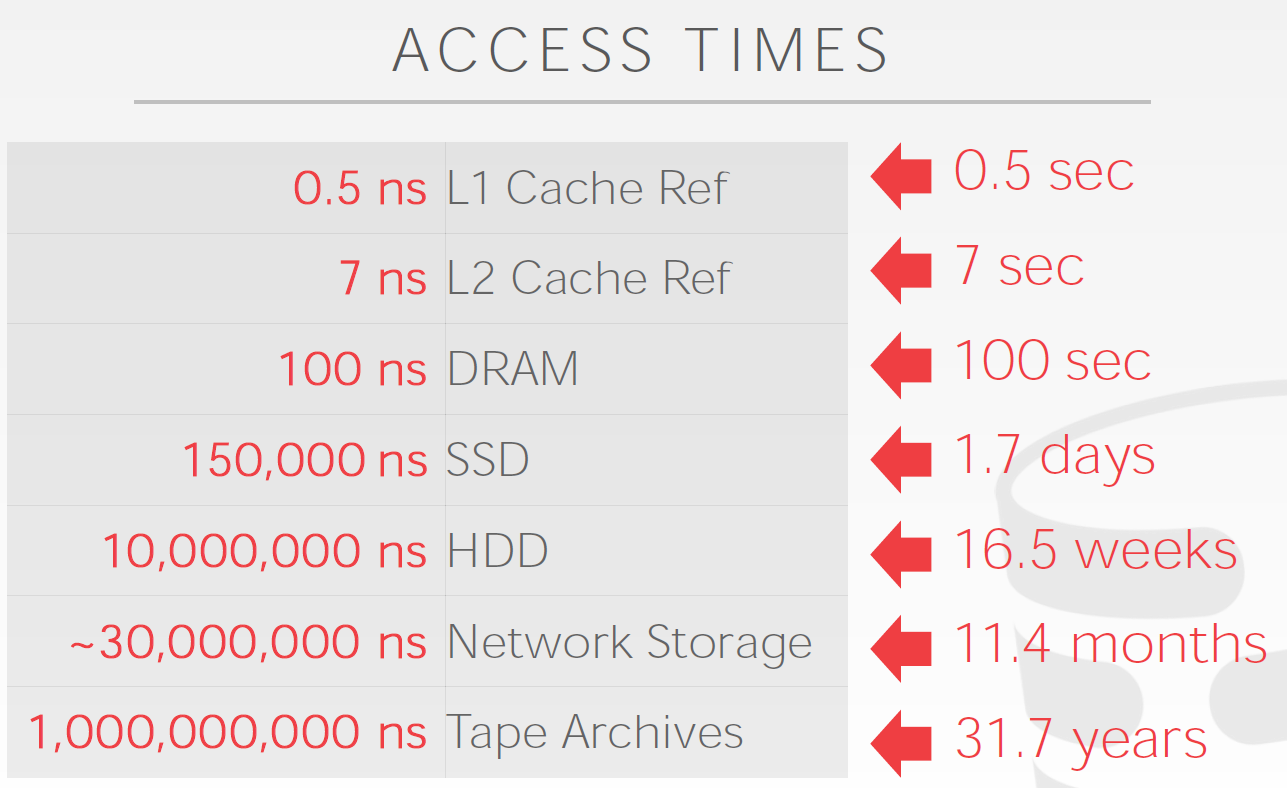
- 直观的理解不同层面的读取速度:
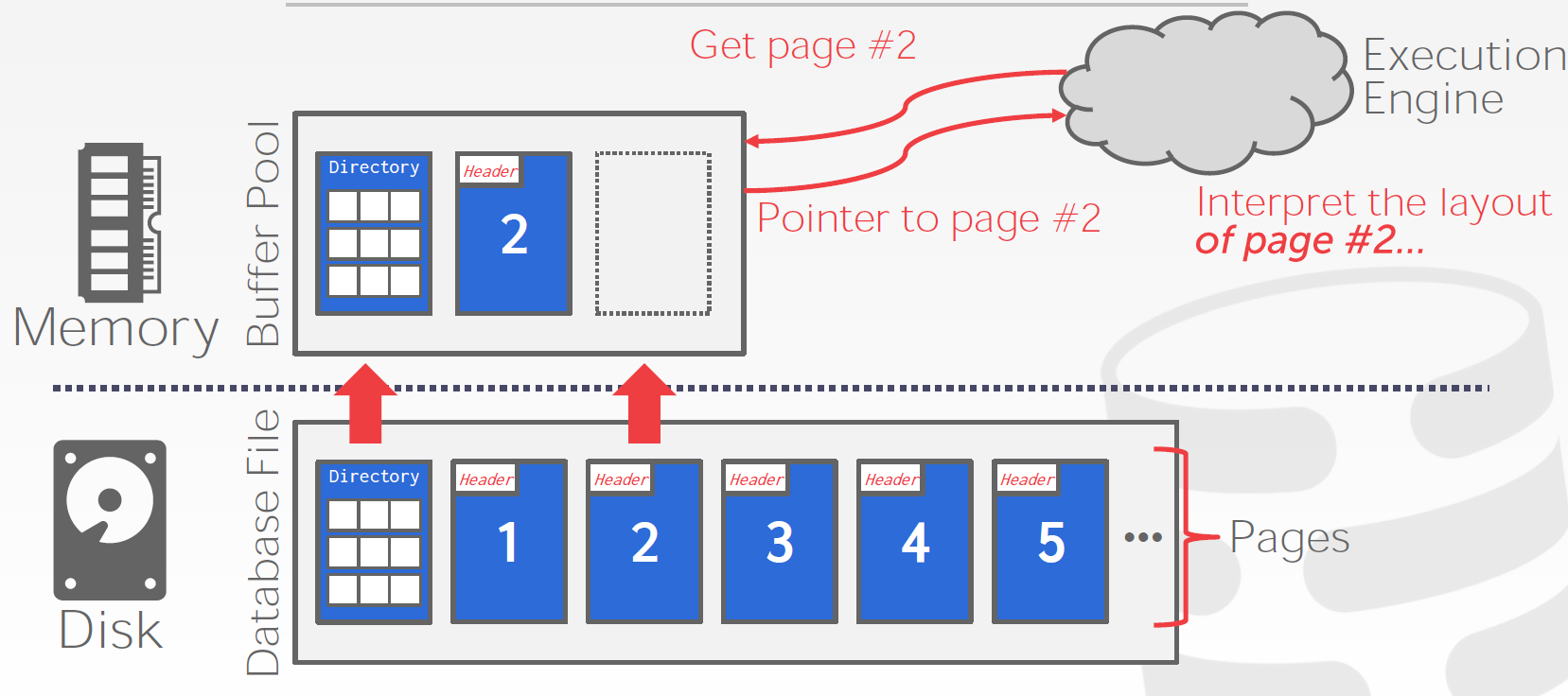
- Goal: Allow the DBMS to manage databases that exceed the amount of memory available. (Create an illusion that all the data is stored in memory )
How it works:
 Syllabus:
Syllabus:
# Why not use the OS?
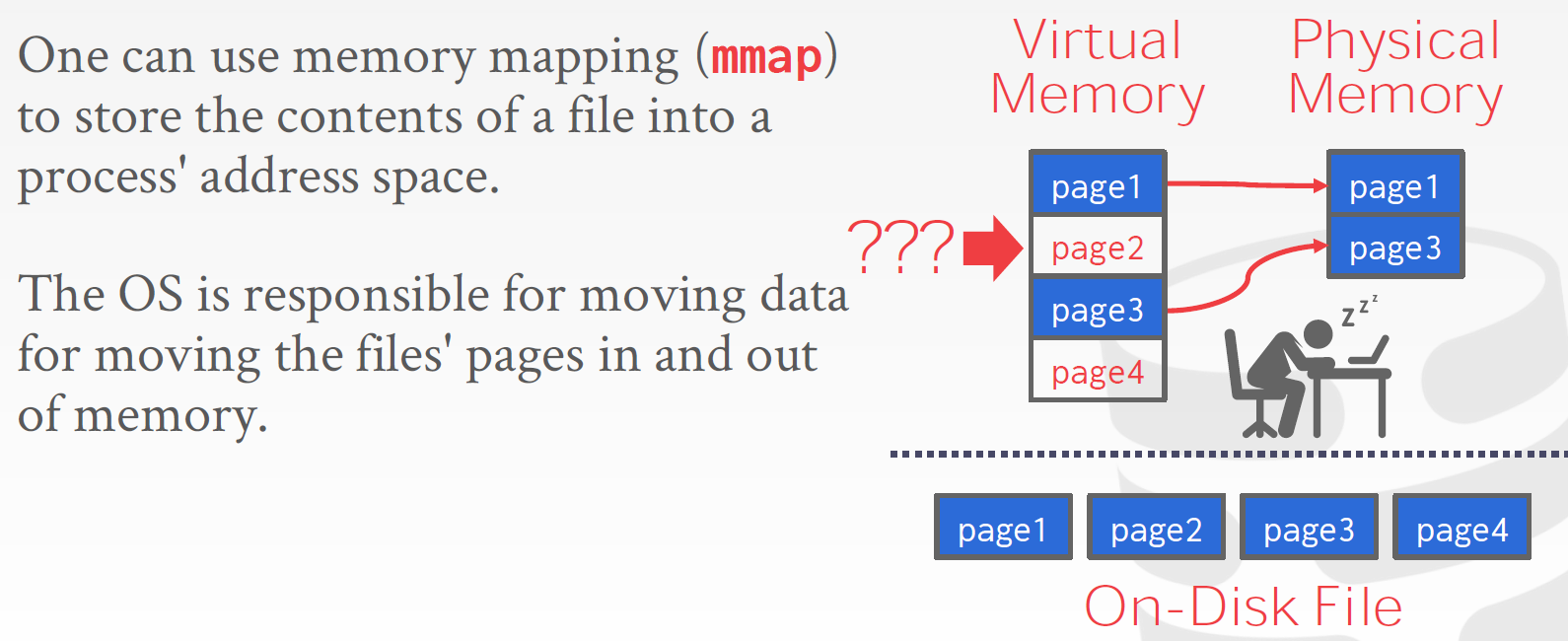
# Virtual Memory?
The OS only sees a bunch of reads and writes, the DBMS (almost) always wants to control things itself and can do a better job at it.
mmap: the way virtual memory works:
Problem #1: How the DBMS represents the database in files on disk:
(Later) Problem #2: How the DBMS manages its memory and move data back-and-forth from disk.
# Problem #1
# File Storage
The DBMS stores a database as one or more files on disk, In the meanwhile, The OS doesn’t know anything about the contents of these files.
# Who do the work?
The storage manager → responsible for maintaining a database’s files. → Some do their own scheduling for reads and writes to improve spatial and temporal locality of pages.
# How?
It organizes the files as a collection of pages.
A page is a fixed-size block of data. → Most systems do NOT mix page types. → Some systems require a page to be self-contained.
Each page is given a unique identifier. → The DBMS uses an indirection layer to map page ids to physical locations.
There are three different notions of “pages” in a DBMS: → Hardware Page (usually 4KB) → OS Page (usually 4KB) → Database Page (512B-16KB)
- 硬件层保证了4KB的原子性, (比如有一次写入操作失败了, 那么失败的范围一定是4KB最小单位的)
# Page Storage Architecture
Different DBMSs manage pages in files on disk in different ways. → Heap File Organization → Sequential / Sorted File Organization → Hashing File Organization
At this point in the hierarchy we don’t need to know anything about what is inside of the pages.
# Heap File Organization
- an unordered collection of pages where tuples that are stored in random order.
- Need meta-data to keep track of what pages exist and which ones have free space.
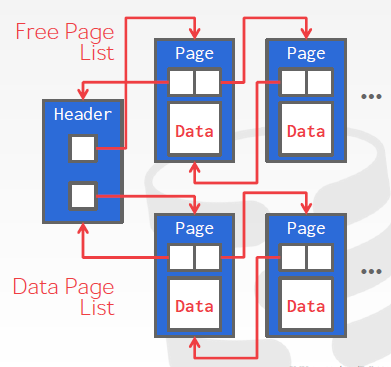
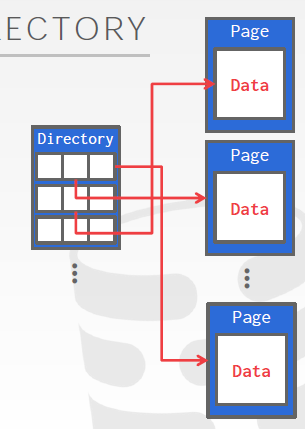
- Two ways to represent a heap file: → Linked List → Page Directory
# Linked List
# Page Directory
# Page Layout

- We have a page header to store meta-data.
# How to organize the data stored inside of the page?
Assume we only store tuples;
Two approaches: → Tuple-oriented → Log-structured
# Tuple-oriented
- It’s a bad idea to store all the tuples linearly:

# Slotted Pages
Instead, the most common layout scheme is called slotted pages.
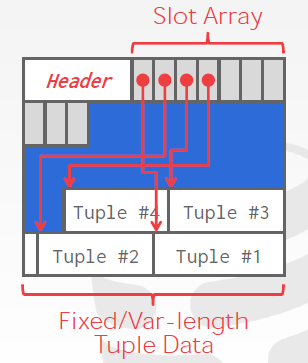
The slot array maps “slots” to the tuples’ starting position offsets.
增长方向:
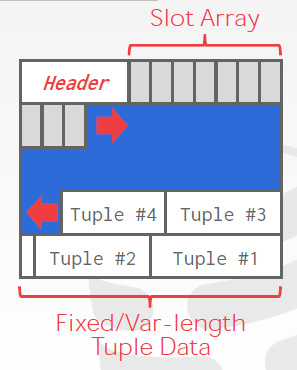
If you delete a slot in the middle, some DBMS clean the empty gap while others don’t.
# Log Structured File Organization
Instead of storing tuples in pages, the DBMS only stores log records. E.g. Insertion Deletion Updates etc.

To read a record, the DBMS scans the log backwards and “recreates” the tuple to find what it needs.
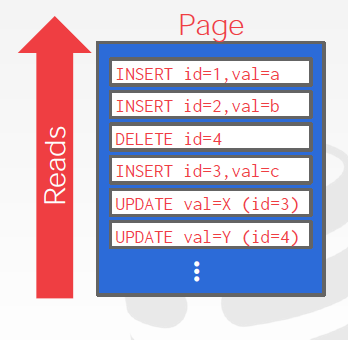
Build indexes to allow it to jump to locations in the log.
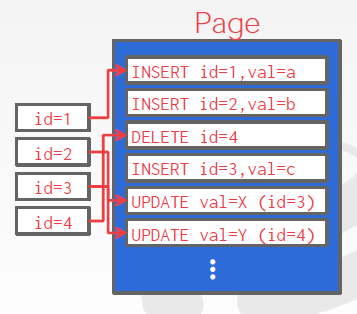
Periodically (周期性地) compact the log.

# Tuple Layout
- A tuple is essentially a sequence of bytes.
- It’s the job of the DBMS to interpret those bytes into attribute types and values.
# Tuple header
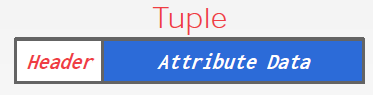 → Visibility info (concurrency control)
→ Bit Map for NULL values.
→ Visibility info (concurrency control)
→ Bit Map for NULL values.
- We do not need to store meta-data about the schema.
# Tuple Data
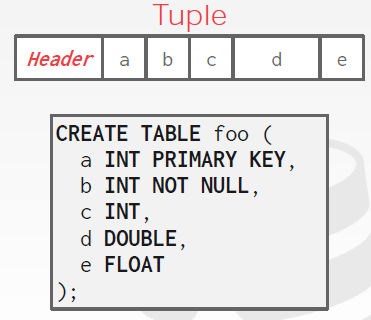
- Stored in the order that you specify them when you create the table.
- This is done for software engineering reasons.
# Denormalized Tuple Dataq

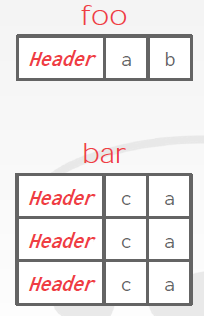
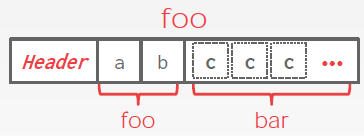
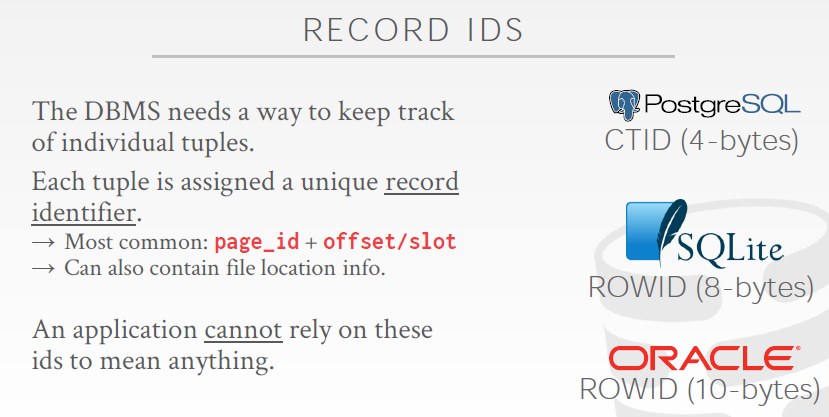
# Record IDs
In order to keep track of individual tuples, each tuple is assigned a unique record identifier.
→ Most common: page_id + offset/slot
→ Can also contain file location info.
An application cannot rely on these ids to mean anything.
It changes!