Part.17_Overfitting_Underfitting(ML_Andrew.Ng.)
# Overfitting Underfitting
Tags: #Overfitting #Underfitting #MachineLearning
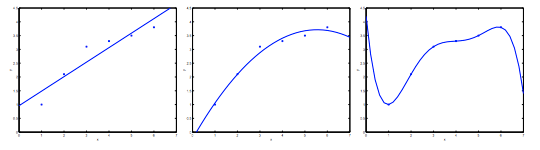
# Underfitting
Underfitting 的另一 种表述是这个模型有 “High Bias”, 直观上理解, 这个模型对数据集有着先入为主的"偏见", “不允许"数据集为二次的, 导致预测效果不好. Bias=Preconception
原因: 模型太简单/使用的特征太少
# Overfitting
Overfitting的另一种表述则是 “High Variance”, 即这个模型有着太多的可能性, 而我们的数据太少, 我们现有的数据不足以确定这个模型 / 基于现有的数据, 这个模型有着很高的变数.
The term high variance is another historical or technical one. But, the intuition is that, if we’re fitting such a high order polynomial, then, the hypothesis can fit, you know, it’s almost as if it can fit almost any function and this face of possible hypothesis is just too large, it’s too variable. And we don’t have enough data to constrain it to give us a good hypothesis.
原因: 模型太复杂
# 解决方法
减少特征数目
- 手动筛选
- 利用降维算法
Regularization 正则化
- 保留所有特征, 但是减小参数的Magnitude
- Regularization works well when we have a lot of slightly useful features.
- 在以前的关于为什么要利用均方误差的笔记里面也有关于Bias_Variance_Trade-off 的阐述:
# 后续思考
- Source:
4.6. 暂退法(Dropout) — 动手学深度学习 2.0.0-beta0 documentation
线性模型的 High Bias 一定程度上是因为线性模型没有考虑到特征之间的交互作用。 对于每个特征,线性模型必须指定正的或负的权重,而忽略其他特征。
深度神经网络位于偏差-方差谱的另一端。 与线性模型不同,神经网络并不局限于单独查看每个特征,而是学习特征之间的交互。 例如,神经网络可能推断“尼日利亚”和“西联汇款”一起出现在电子邮件中表示垃圾邮件, 但单独出现则不表示垃圾邮件。
即使我们有比特征多得多的样本,深度神经网络也有可能过拟合。 2017 年,一组研究人员通过在随机标记的图像上训练深度网络。 这展示了神经网络的极大灵活性,因为人类很难将输入和随机标记的输出联系起来, 但通过随机梯度下降优化的神经网络可以完美地标记训练集中的每一幅图像。 想一想这意味着什么? 假设标签是随机均匀分配的,并且有 10 个类别,那么分类器在测试数据上很难取得高于 10%的精度, 那么这里的泛化差距就高达 90%,如此严重的过拟合。
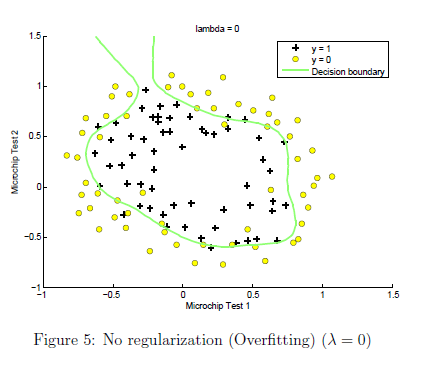
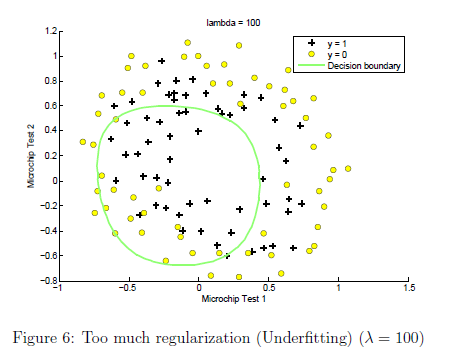
吴恩达练习二里面的例子: