可视化损失函数的困难
# 可视化损失函数的困难
- 我们先来看看Loss Function的形式: $$L_{\theta}\space (\hat{y},\space y)=\cdots$$
里面有四个组成部分: $L, \theta, \hat{y}$ 和 $y$
需要牢记的一点是: 选择Loss Function $L$ 的时候选择的是"计算方式", 也就是我们怎样计算模型输出 $\hat y$ 和真实值 $y$, 而损失函数实际上是关于权重 $\theta$ 的函数, 我们在反向传播的时候是对学习目标 $\theta$ 求梯度, 而直观的梯度下降法也是在 $L$ 关于 $\theta$ 的图像上逐步下降的.
样本 $y$ 和损失函数 $L$ 影响着整个梯度地形图的形状, 而模型输出 $\hat{y}$ 和权重 $\theta$ 则代表等高线图里面的一个小人, 在训练时不断移动.
容易忽略的一点是: 影响"损失地形图"的不仅有 $L$, 还有样本 $y$. 没有训练样本, 损失函数只是一个计算方式而已.
要得到"损失地形图", 需要经过如下几步:
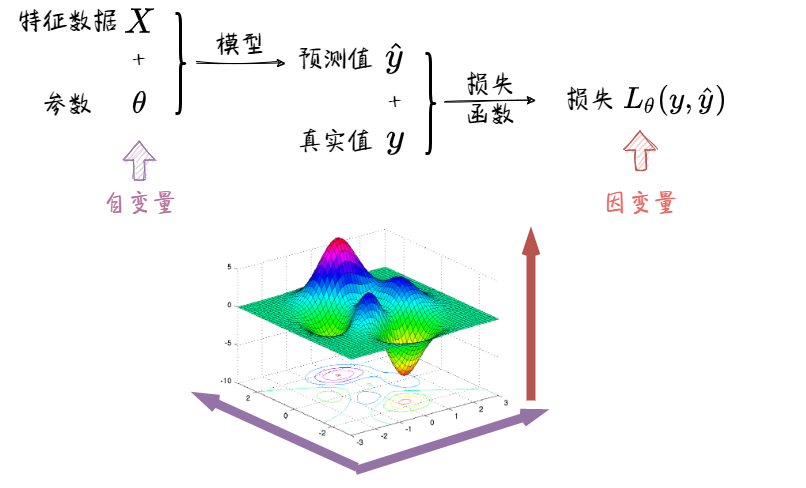
可以看到: 因为参数 $\theta$ 需要经过模型和损失函数两次变换, 而且模型的参数 $\theta$ 通常数目庞大, 所以实际图像是非常复杂的.
尽管实际图像非常复杂, 我们在学习的时候还是可以构造简单的特例, 来理解模型训练中的一些问题, 比如: