D2L-21-模型容量
# 模型容量(复杂度)
2022-02-12
Tags: #DeepLearning
Link: Part.17_Overfitting_Underfitting(ML_Andrew.Ng.)
# 概念
- 模型容量就是模型的复杂度, 也就是一个模型的Variance.
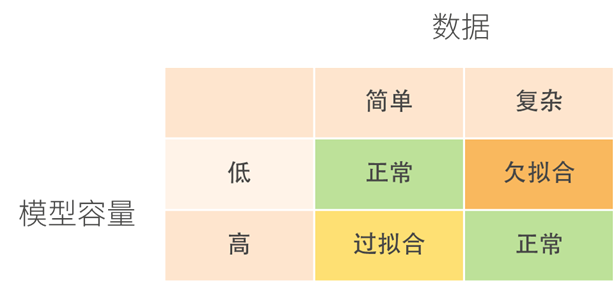
- 模型容量和数据的复杂度应该对应, 两者的不匹配容易导致过拟合与欠拟合问题
- 下图是两种损失随着模型复杂度的变化(注意横轴代表的是不同复杂度的模型, 不要和训练的Loss曲线搞混).

- 可以看到对于同一个数据集, 过于复杂的模型虽然有着更小的训练损失, 但是有了更大的泛化损失, 则说明模型过分契合训练集了, 学习到了训练集的一些误差等等, 太过于灵活(High variance), 出现了过拟合
- 而如果模型过于简单, 则训练损失和泛化损失都很高, 说明模型能力不够, 学习不到足够的知识, 模型对于数据的偏见(Bias)太高了
- 可以看到对于同一个数据集, 过于复杂的模型虽然有着更小的训练损失, 但是有了更大的泛化损失, 则说明模型过分契合训练集了, 学习到了训练集的一些误差等等, 太过于灵活(High variance), 出现了过拟合
# 模型容量
# 估计模型容量
- 我们很难比较不同类型模型的容量差别: 比如树模型和神经网络.
- 影响模型容量的两个因素:
- 参数的数量
- 参数值的变化范围
# 模型容量的评价标准
- VC维是对一个可学习分类函数空间的能力(复杂度,表示能力等)的衡量。
- 它定义为算法能“打散”的点集的势的最大值。
# 数据复杂度
评价数据复杂度的一些方面:
- 样本的个数
- 一个样本元素的个数
- 时间, 空间结构
- 样本分类的多样性