D2L-40-AlexNet
# AlexNet
2022-03-02
Tags: #DeepLearning #AlexNet #CNN #ImageNet

# 模型解析
# 对比LeNet
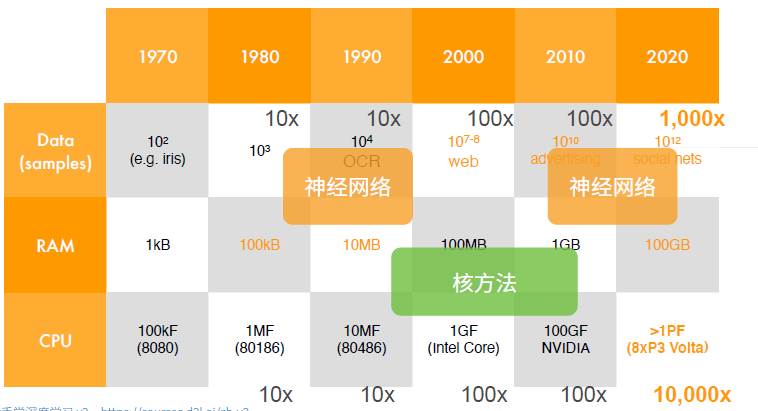
- 最重要的是, AlexNet导致了计算机视觉方法论的改变: 从核方法到深度神经网络, 开启了神经网络的第二次热潮
- 对比LeNet, AlexNet的主要特点有:
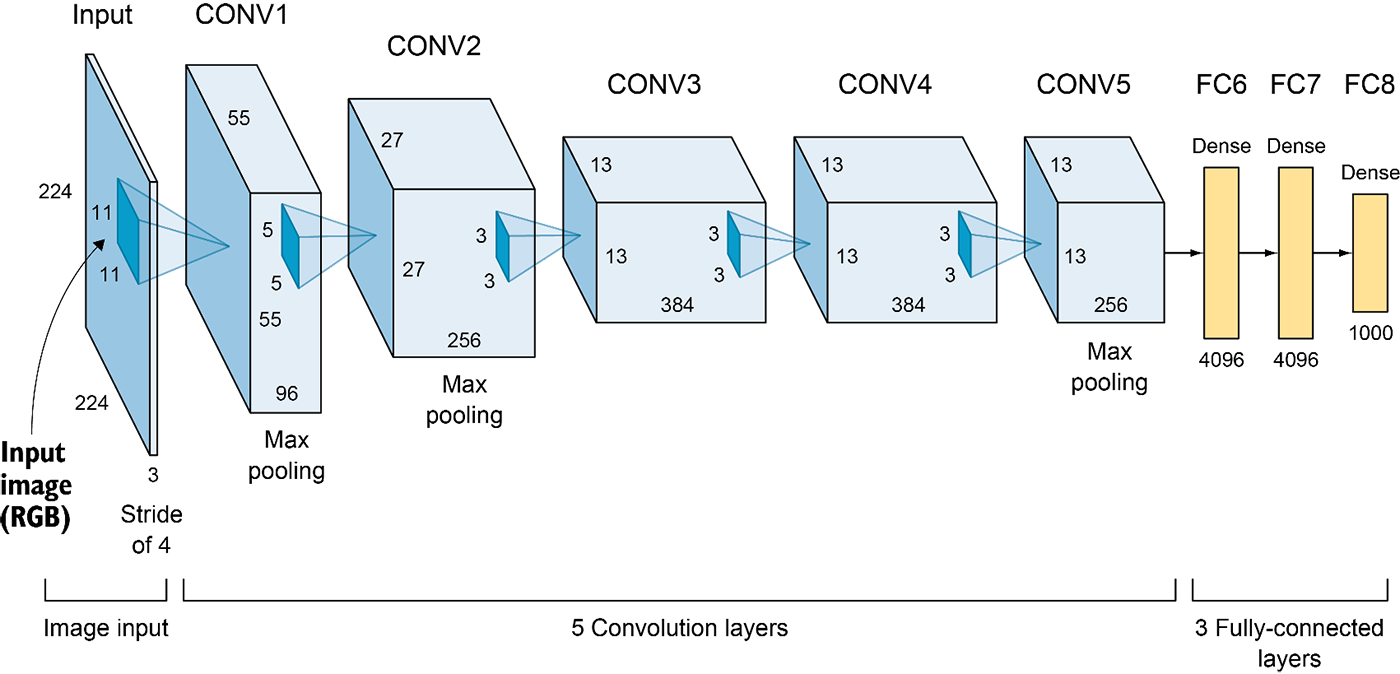
# 网络结构的改进
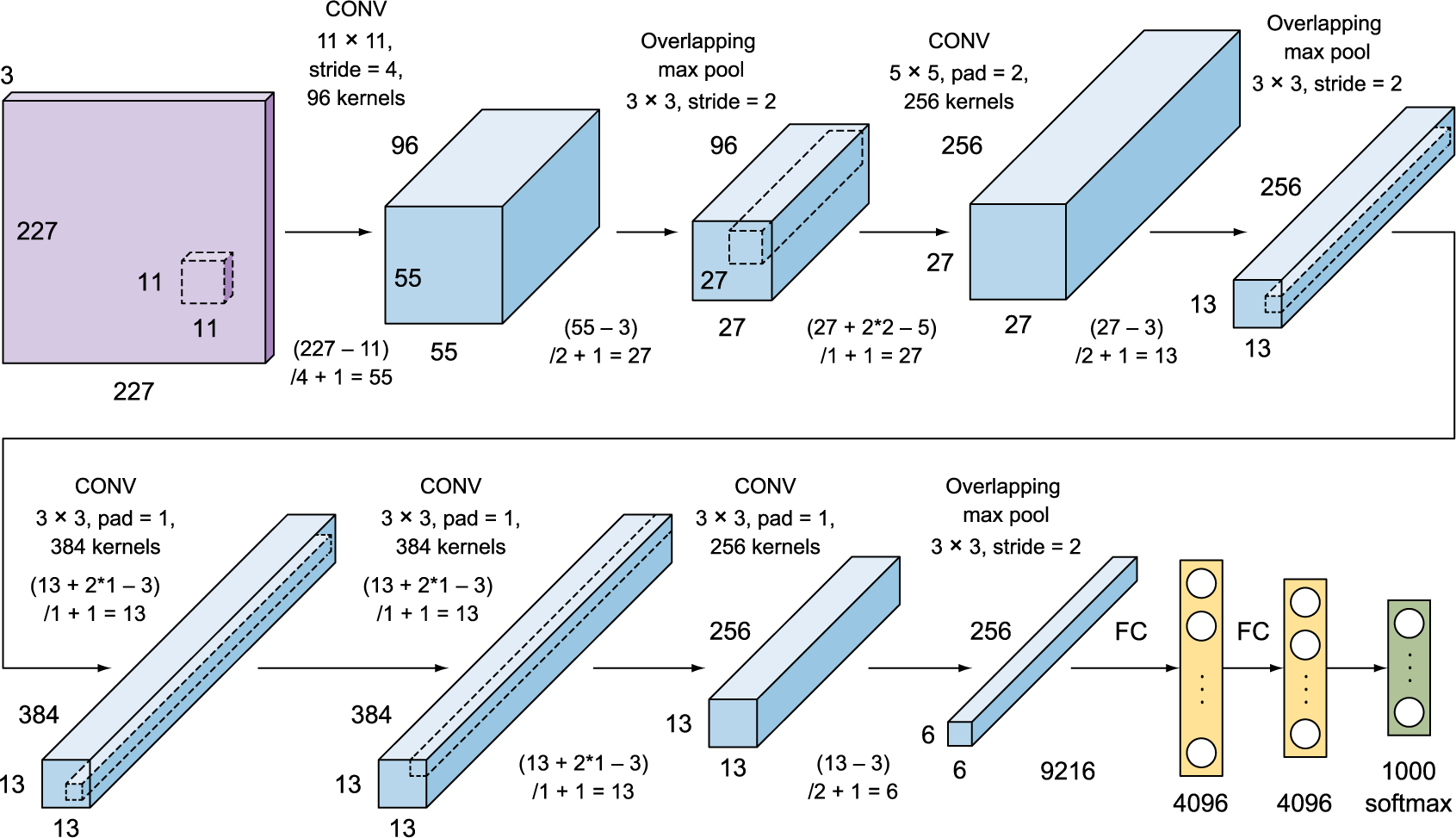
- ImageNet数据集的尺寸更大了, 硬件条件也更好了, 这也推动AlexNet的输入增大到了 $224\times224$.4 (相比之下 LeNet 的MNIST只有 $28\times28$)
- 图像大了, 需要捕获的目标也变大了, 卷积核($11\times11$)和池化层的窗口($3\times3$)自然也增大了, Stride也相应增加.
- 图像大了, 数据集更大了, 信息也更多了, 这使得AlexNet的通道数几乎是LeNet的十倍
- 新增加的三个卷积层让AlexNet比LeNet更深
- 在最后一个卷积层后有两个全连接层,分别有4096个输出。 这两个巨大的全连接层拥有将近1GB的模型参数。
 3
3
# 激活函数
- 此外,AlexNet将Sigmoid激活函数改为更简单的ReLU激活函数。
- 一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。
- 另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。
- 当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。 相反,ReLU激活函数在正区间的梯度总是1。 因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。5
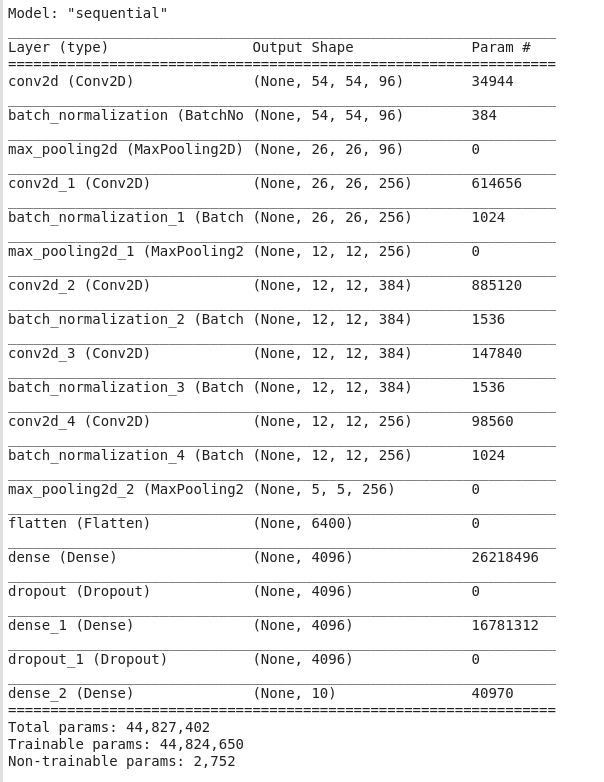
# 容量控制和预处理
- AlexNet通过Dropout控制全连接层的模型复杂度,而LeNet只使用了权重衰减。
| |
- 同时为了进一步扩充数据,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。 这使得模型更健壮,更大的样本量有效地减少了过拟合。

# Side Notes
- 受限于当时的硬件条件, AlexNet的原始模型使用了两个GPU同时计算, 在网络架构图里表示为双数据流设计:
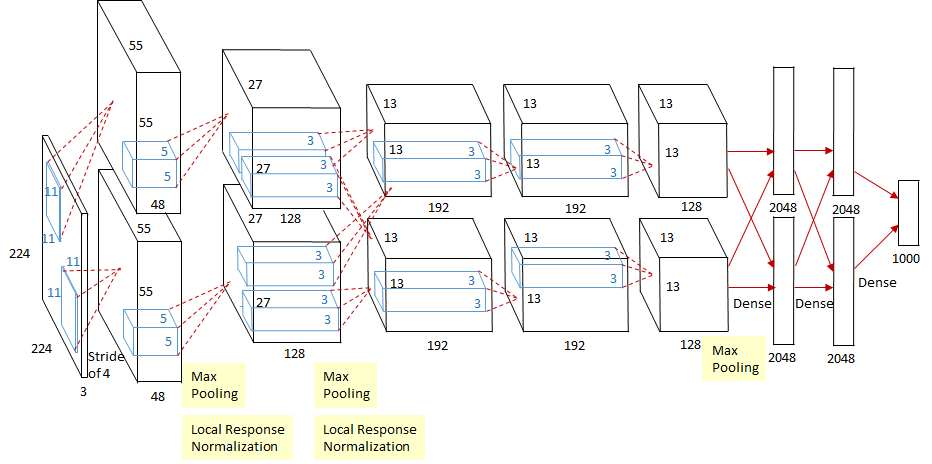 7
7- 我们现在可以将两条路合并, 精简为只使用一个GPU的模型.
# 不足
- 虽然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。
- 在后面的一些研究里面, 我们逐渐总结出一些常用于设计深层神经网络的启发式概念。
- 模块化: VGG
- 去除全连接层: NiN
- 并行连接与稀疏性: GoogLeNet(Inception)
- 残差连接: ResNet
# Origin
- AlexNet is named after Alex Krizhevsky

- Paper: PDF(zotero://select/items/@krizhevsky2012imagenet) A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks (AlexNet),” Advances in neural information processing systems, vol. 25, 2012.
Dropout并不是在这篇文章里面提出来的, 但是的确是同一帮人提出来的 ↩︎
5 Advanced CNN architectures · Deep Learning for Vision Systems ↩︎
AlexNet的输入大小好像有点不统一, 在论文里面是 $224\times224$ , 但是如果Padding=1, Stride=4的话, 下一个卷积层的大小是 $54.5$, 不是一个整数, 需要向下取整得到54. 所以有的地方就把输入改成了227, 这样算出来就刚好是54. ↩︎
7.1. 深度卷积神经网络(AlexNet) — 动手学深度学习 2.0.0-beta0 documentation ↩︎
GitHub - ishanExtreme/AlexNet-Visualization: Visualizing layer output of AlexNet model trained on cifar-10 dataset ↩︎