D2L-42-NiN
# Network in Network - NiN
2022-03-04
Tags: #DeepLearning #NiN #CNN
![]()
# 用卷积代替全连接
# 动机
# 全连接层很贵 (参数很多)
一层卷积层需要的参数为:
卷积层后面第一个全连接层的参数为: $$in_Channel\times in_Height\times in_Width\times num_of_Hidden_Units$$
对比 :

# 全连接层损失了空间信息
- 这一点很好理解: 由卷积层转化到全连接层, 需要将卷积输出全部Flatten为一个一维向量. 而这意味着放弃了卷积层里面的空间信息.
# 1x1 卷积相当于(单像素上的)全连接
![]()
# 网络结构
- 交替使用NiN块和步幅为2的最大池化层
- 逐步减小高宽和增大通道数

- 逐步减小高宽和增大通道数
# 分块
- 和VGG一样, NiN网络也采用了分块的规范化网络结构, 一个NiN块包括一个普通卷积层与两个连续的 $1\times1$ 卷积层.
1 2 3 4 5 6def nin_block(in_channels, out_channels, kernel_size, strides, padding): return nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding), nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())1超参数主要调节的是第一个卷积层, 后面两个$1\times1$的卷积层不改变通道数.
# 全局平均池化层 global average pooling layer
其他网络里面通常将最后一层的隐藏层输出作为 Logit 输入到Softmax里面得到预测概率, 但是NiN没有全连接层, 又怎么得到输出标签呢?
NiN网络将每一个通道的所有像素取平均值, 作为最后的输出. 这就相当于一个窗口大小是整个输入的平均池化层, 也称 全局平均池化层(Global Average Pooling layer)
所以NiN网络最后输出的通道数等于预测的类别数, 通过一个全局平均池化层(GAP)来得到每个类别的原始输出.
这也是为了避免使用全连接层, 减少参数数量的一个操作. 当然也同时减少了计算量, 防止过拟合
# 与AlexNet相似的超参数
- 最初的NiN网络是在AlexNet后不久提出的,显然从中得到了一些启示。 NiN使用窗口形状为11×11、5×5和3×3的卷积层,输出通道数量与AlexNet中的相同。 每个NiN块后有一个最大汇聚层,汇聚窗口形状为3×3,步幅为2。3
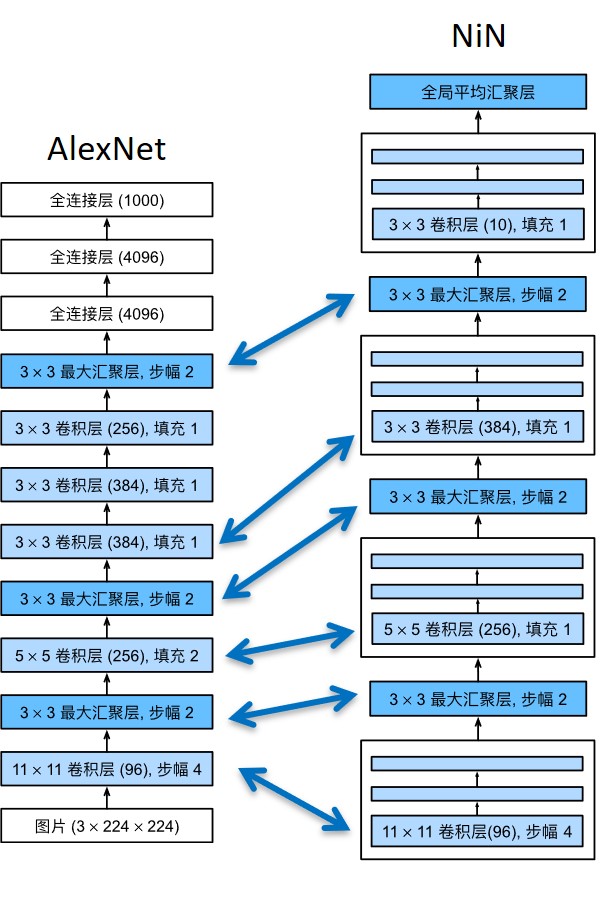
# 模型的特性
- 参数少, 模型不容易过拟合, 同时也减少了计算量.
- 但是由于增加了大量的1x1卷积, NiN的训练时间更长, 总的计算量也并没有比AlexNet少.