D2L-43-GoogLeNet(Inception)
# GoogLeNet
Tags: #DeepLearning #CNN #GoogLeNet-Inception
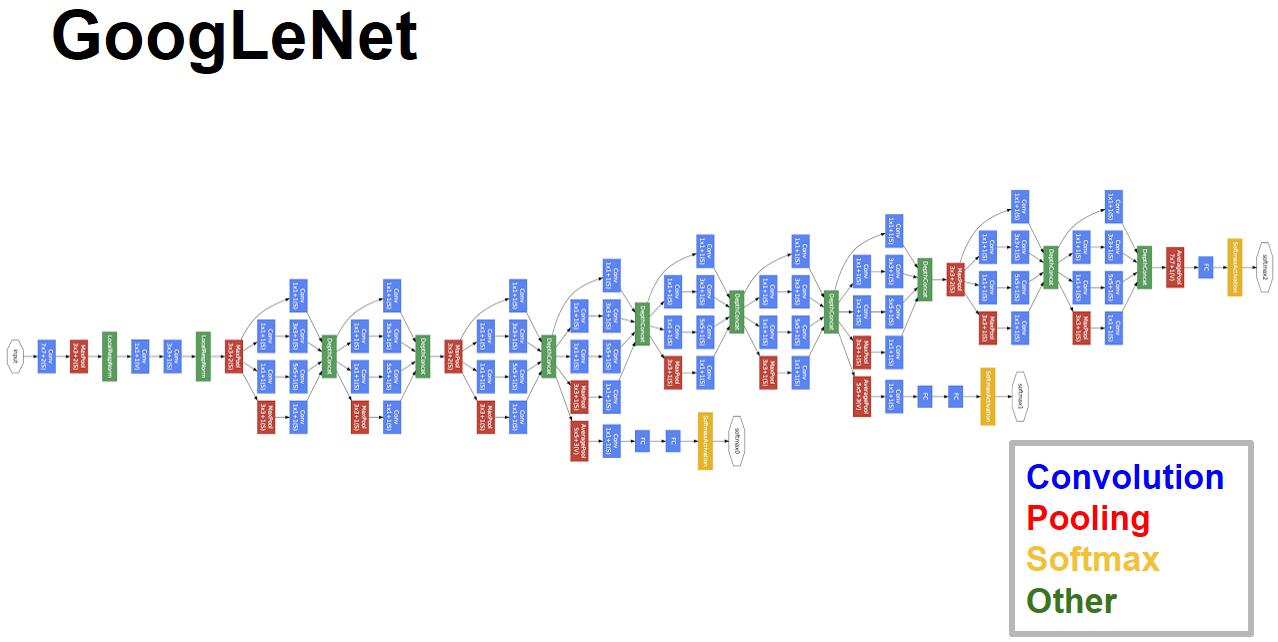
GoogLeNet是一个含并行连结的网络, 其核心组成部分为"Inception块".
Inception块组合使用了不同大小的卷积核, 试图用现有的稠密结构(Dense Components)来构建一个"最佳的局部稀疏网络".
- 局部: 多个Inception块拼接构成最后的GoogLeNet
- 稀疏: 也就是具有随机性的结构1
GoogLeNet还具有较高的计算效率, 这主要得益于Inception块里面不含全连接层.
# Inception Block

GoogLeNet的基本组成部分称为Inception块(Inception block)。这得名于电影《盗梦空间》(Inception)2.
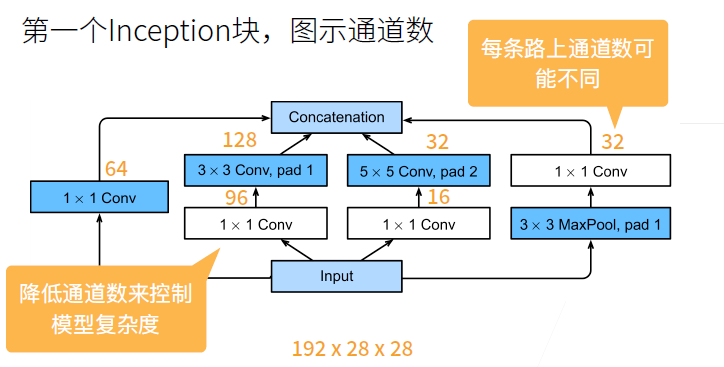
Inception块由四条并行路径组成。 前三条路径使用窗口大小为 $1×1$、$3×3$ 和 $5×5$ 的卷积层,从不同空间大小中提取信息。 中间的两条路径在输入上执行 $1×1$ 卷积,以减少通道数,从而降低模型的复杂性。
# 并行连结: 不同卷积核的组合
- Inception并行使用了不同大小的卷积层, 可以从不同的层面抽取信息.
- 尽管窗口大小是不同的, 我们也可以调节Stride和Padding来使输入和输出高宽相等
- 不同路径的输出在通道上进行拼接(将通道数相加).
- 不同路径的通道数占比是不一样的
 3
3
- 不同路径的通道数占比是不一样的
# Add Sparsity using Dense Building Blocks
提升网络性能的一个简单方法就是增大网络的规模, 但是规模的增长会带来网络体积与计算开销的剧烈增长. 作者认为若要从根本上解决这一问题, 我们需要舍弃稠密的结构(比如全连接层和卷积), 采用更为稀疏的网络架构.
- 一些理论性的工作1也阐述了一种最优的神经网络结构: 对高度相关的输出进行逐层聚类. 这同时也和神经科学里面的Herbbian principle很类似: “Neurons that fire together, wire together.”
为了构建稀疏的(具有随机性的)网络, 同时利用好现有硬件对于密集矩阵的高计算性能, 作者提出了Inception块.
下图表示了Inception的原始设计:
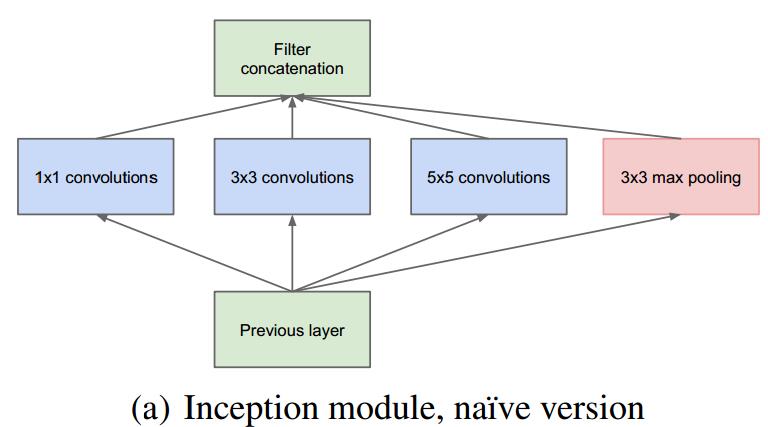
同时对上图做以下说明:4
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
- 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
- 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
# 1x1卷积: 减少通道的数量
- 但是 $3×3$ 和 $5×5$ 的卷积依然是昂贵的. 为此,文章借鉴
NiN,采用1x1卷积来减少通道数.
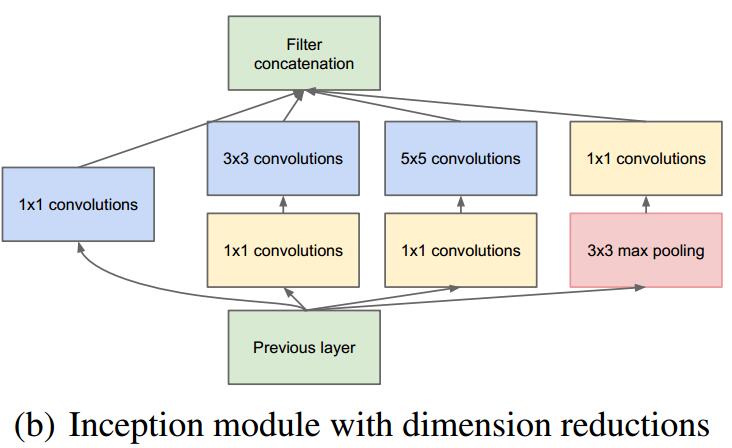
- 额外增加的1x1卷积还为网络增加了额外的非线性性(Non-linearity). 作者说 1x1卷积层 的通道融合效果也使得之后的卷积操作能够在融合后的图像上面进行特征提取操作, 这或许能够改进效果.
# Computational Efficiency
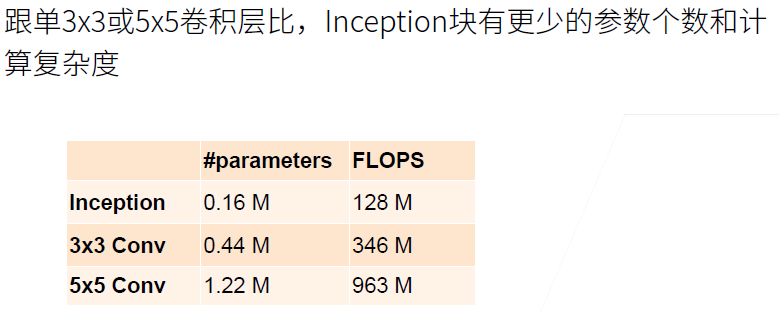
# GoogLeNet
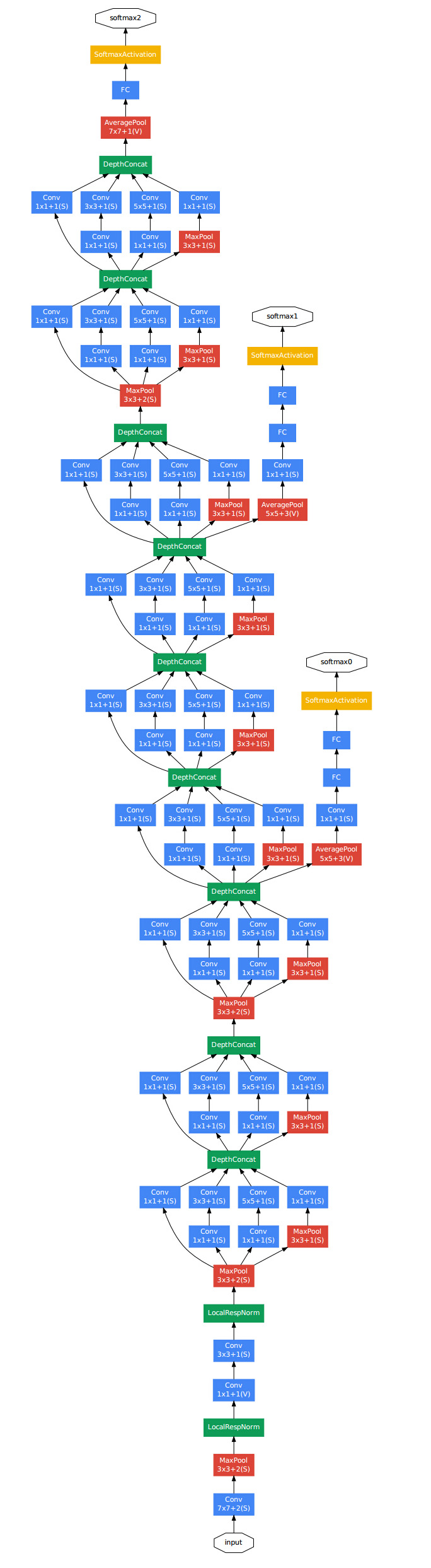
- 将多个Inception块组合起来, 我们便得到了GoogLeNet, 包含5段9个Inception块
- GoogLeNet并没有一开始就使用Inception块, 作者认为这样也许更好, 但也不是一定的
- 网络的最后采用了类似于NiN的全局平均池化层, 但是为了便于迁移学习与参数调整, 最后还是加上了一个全连接层.
- 每一个Inception块都有通道数量上的细微差别, 除了上面提到的调整方向以外, 这些参数其实很难合理解释.
- 在不同的Inception块之间有时还有3x3池化层用于减小图像尺寸.

- GoogLeNet一共有 22 层
- Only 5 million parameters!
- 12x less than AlexNet
- 27x less than VGG-16
- ILSVRC’14 classification winner (6.7% top 5 error)
# Auxiliary Networks: Not Important
- 原始的网络里面为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。但是现在有了更好的训练方法,这些特性不是必要的。

# Future Improvements
- Inception-BN (v2) - 使用 batch normalization
- Inception-V3 - 修改了Inception块
- 替换 $5 \times 5$ 为多个 $3 \times 3$ 卷积层
- 替换 $5 \times 5$ 为 $1 \times 7$ 和 $7 \times 1$ 卷积层
- 替换 $3 \times 3$ 为 $1 \times 3$ 和 $3 \times 1$ 卷积层
- 更深
- Inception-V4 - 使用残差连接
S. Arora, A. Bhaskara, R. Ge, and T. Ma, “Provable bounds for learning some deep representations,” in International conference on machine learning, 2014, pp. 584–592. PDF(zotero://select/items/@arora2014provable) ↩︎
knowyourmeme.com/memes/we-need-to-go-deeper 电影中有这么一句话: “We need to go deeper”。 ↩︎
27 含并行连结的网络 GoogLeNet / Inception V3【动手学深度学习v2】哔哩哔哩_bilibili ↩︎