D2L-62-BLEU (Bilingual Evaluation Understudy)
# BLEU (Bilingual Evaluation Understudy)
2022-04-20
Tags: #BLEU #DeepLearning
BLEU 是一种用于评价输出序列质量的评价指标, 其特点在于它考虑到了序列长度和预测难度的关系.
BLEU 通过综合"不同n-gram在结果中的成功次数"来评价最终质量的好坏.
# 定义
$$ \exp\left(\min\left(0, 1 - \frac{\mathrm{len}{\text{label}}}{\mathrm{len}{\text{pred}}}\right)\right) \prod_{n=1}^k p_n^{1/2^n}$$
其中:
- $\mathrm{len}_{\text{label}}$ 表示标签序列中的词元数
- $\mathrm{len}_{\text{pred}}$ 表示预测序列中的词元数
- $k$ 是最长的 $n$ 元语法的长度。
另外,用 $p_n$ 表示 $n$ 元语法的精确度,它是两个数量的比值: $$p_n=\frac{\operatorname{Num}^{(n)}{match}}{\operatorname{Num}^{(n)}{total}}$$
- 分子是预测序列与标签序列中成功匹配的 $n$ 元语法个数,
- 分母是预测序列里面n-gram的总个数。
举个例子,给定标签序列 $A$、$B$、$C$、$D$、$E$、$F$ 和 预测序列 $A$、$B$、$B$、$C$、$D$, 我们有 $p_1 = 4/5$、$p_2 = 3/4$、$p_3 = 1/3$ 和 $p_4 = 0$。
# 解释
# 上限: 完美情况
当两个序列完全相同的时候, BLEU=1.
# 系数: 惩罚短的预测
$$\exp\left(\min\left(0, 1 - \frac{\mathrm{len}{\text{label}}}{\mathrm{len}{\text{pred}}}\right)\right)$$
- 这个系数的作用是: 为更长的$n$元语法的精确度分配更大的权重。
- 例如,当$k=2$时,给定标签序列$A$、$B$、$C$、$D$、$E$、$F$ 和预测序列$A$、$B$,尽管$p_1 = p_2 = 1$,但是惩罚因子$\exp(1-6/2) \approx 0.14$会降低BLEU。
# 底数: 也在惩罚短的预测
- 当$p_n$固定时(也就是假设所有n-gram的预测成功比率都是一样的),$p_n^{1/2^n}$会随着$n$的增长而增加(原始论文使用$p_n^{1/n}$), 所以n越大占比越大.
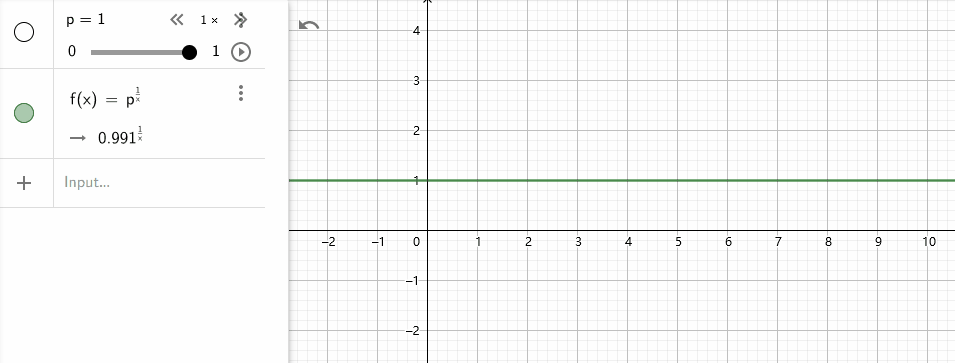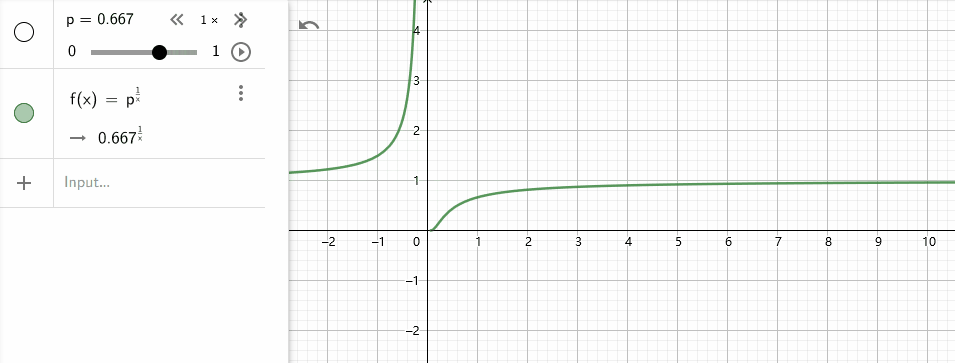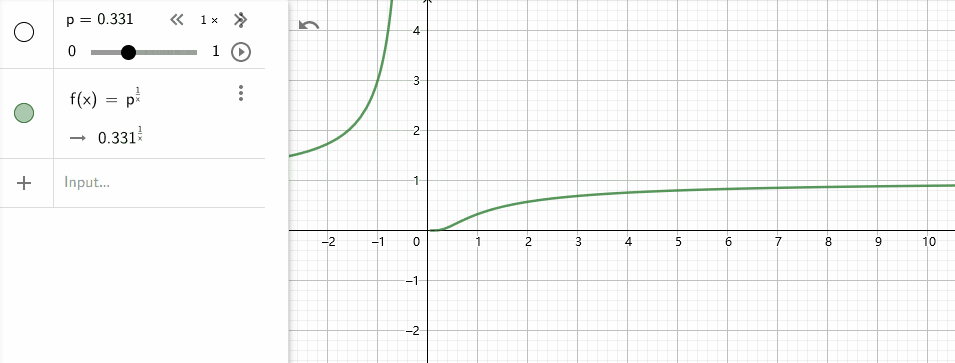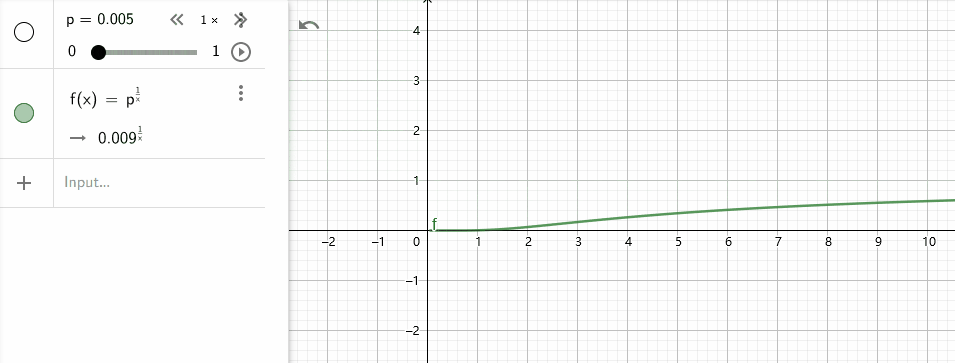 1
1
# 代码实现
| |