D2L-68-Additive Attention
# 加性注意力
2022-04-21
Tags: #Attention #DeepLearning
一般来说,当Query和Key是不同长度的矢量时,我们可以使用Additive Attention来作为Scoring Function。
给定查询 $\mathbf{q} \in \mathbb{R}^q$ 和键 $\mathbf{k} \in \mathbb{R}^k$,加性注意力(additive attention)的评分函数(Scoring Function)为 $$a(\mathbf q, \mathbf k) = \mathbf w_v^\top \text{tanh}(\mathbf W_q\mathbf q + \mathbf W_k \mathbf k) \in \mathbb{R},$$
函数输出的是一个标量. 其中可学习的参数是 $\mathbf W_q\in\mathbb R^{h\times q}$、$\mathbf W_k\in\mathbb R^{h\times k}$ 和 $\mathbf w_v\in\mathbb R^{h}$. 前两个权重分别将 Query 和 Key 映射为长度为 $h$ 的向量, 然后 $\mathbf w_v$ 将向量映射为value 对应的注意力权重.
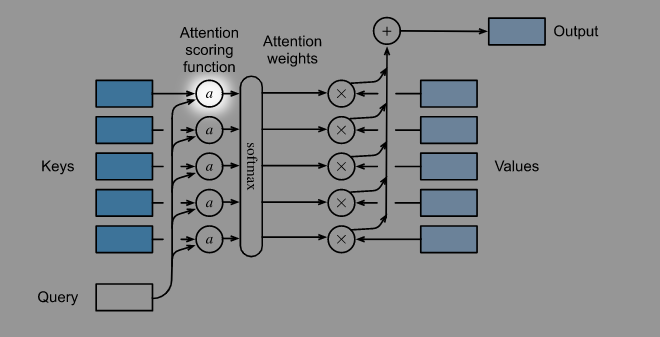
下图展示了Additive Attention是怎样等价于一个单隐藏层的MLP的.
- (图中简化为一个 $k\times1$ 的key和一个 $q\times1$ 的query)

- (图中简化为一个 $k\times1$ 的key和一个 $q\times1$ 的query)
注意上面的MLP和下图的对应关系, 一个Query需要和所有的Keys分别计算一次Score.
# 通用形式
- 在实际应用中, Scoring function需要面对Batch形式输入的Keys and Queries, 并且每一个Batch里面都有多个Keys and Queries.
| |
- 在一个Batch里面, 我们需要计算每一个Key和每一个Query的注意力分数, 这可以通过PyTorch里面的Broadcasting机制来巧妙地实现:
| |
- 其中
masked_softmax对于每一个Query取前valid_lens个 “key-value” pair
可视化Softmax的结果: attention_weights如下:
| |

