D2L-69-Scaled Dot-Product Attention
# 缩放的点积注意力
2022-04-21
Tags: #Attention #DeepLearning
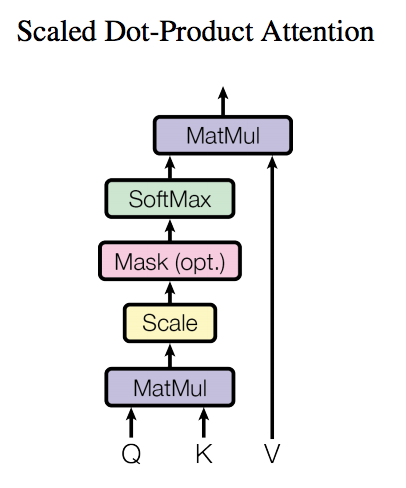
相比Additive Attention, 使用点积可以得到计算效率更高的Scoring Function. 但是点积操作要求查询和键具有相同的长度 $d$。
我们知道 内积可以衡量两个向量之间的相似程度, 所以我们可以这样解读缩放点积注意力:
- 注意力机制是Values的一个加权平均, 而缩放点积注意力会赋予和 Query 更相似的 Key-Value Pair 更高的权重.
假设Query $\mathbf q$ 和Key $\mathbf k$ 的所有元素都是独立的随机变量,并且均值为 $0$, 方差为 $1$. 则它们的点积 $\mathbf q^\top\mathbf k$ 内元素的均值为 $0$,方差为 $d$。
- 为确保结果的方差仍为 $1$,我们将点积除以 $\sqrt{d}$,就得到了缩放点积注意力(scaled dot-product attention)Scoring Function: $$a(\mathbf q, \mathbf k) = \frac{\mathbf{q}^\top \mathbf{k}} {\sqrt{d}}$$
缩放点积注意力里面是没有任何参数的, 这是它和加性注意力的一个区别.
# 通用形式
在实践中,我们通常从小批量的角度来考虑提高效率
例如一个Batch需要基于 $n$ 个 Query 和 $m$ 个 Key-value pair 计算注意力,其中Query和Key的长度为 $d$,Value的长度为 $v$, 查询 $\mathbf Q\in\mathbb R^{n\times d}$、键 $\mathbf K\in\mathbb R^{m\times d}$ , 值 $\mathbf V\in\mathbb R^{m\times v}$ .
- 则缩放点积注意力为: $$ \mathrm{softmax}\left(\frac{\mathbf Q \mathbf K^\top }{\sqrt{d}}\right) \mathbf V \in \mathbb{R}^{n\times v}.$$
代码实现:
| |
- 在代码里面我们还使用了 Dropout来进行正则化
不是图源, 但是我是在这里看到的 Attention机制详解(二)——Self-Attention与Transformer - 知乎 ↩︎