D2L-70-Seq2Seq with Attention - Bahdanau Attention
# 含注意力机制的Seq2Seq
2022-04-22
Tags: #Seq2Seq #Attention #DeepLearning #RNN
# Motivation
- 在
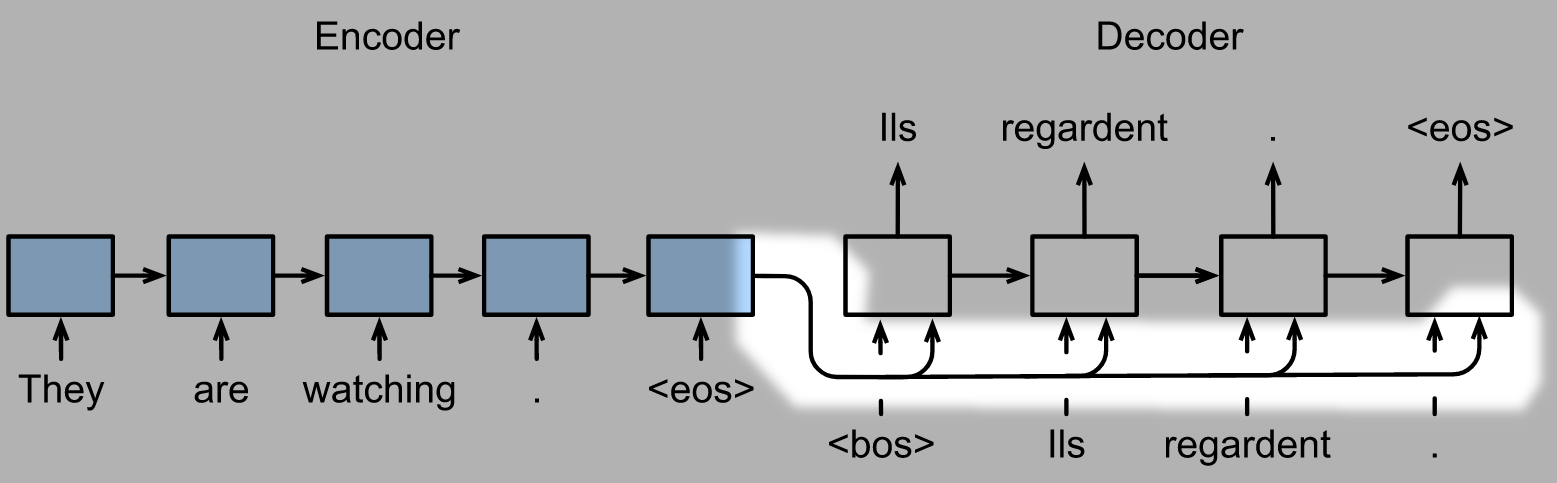
Seq2Seq模型里面, Encoder向Decoder传递的仅仅是最后一个时间步的隐状态, 也就是上下文变量 $\mathbf c= \mathbf{h}_T$, 我们假设里面已经包含了输入序列的所有信息:
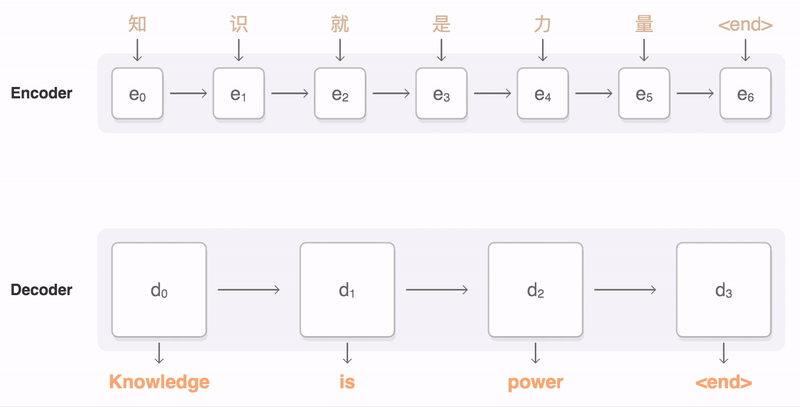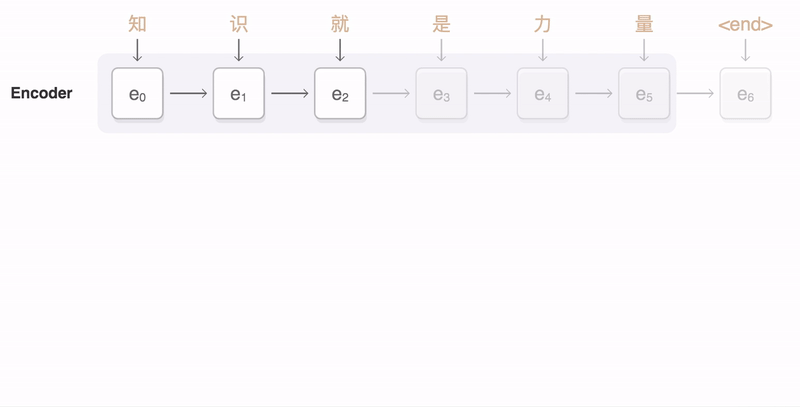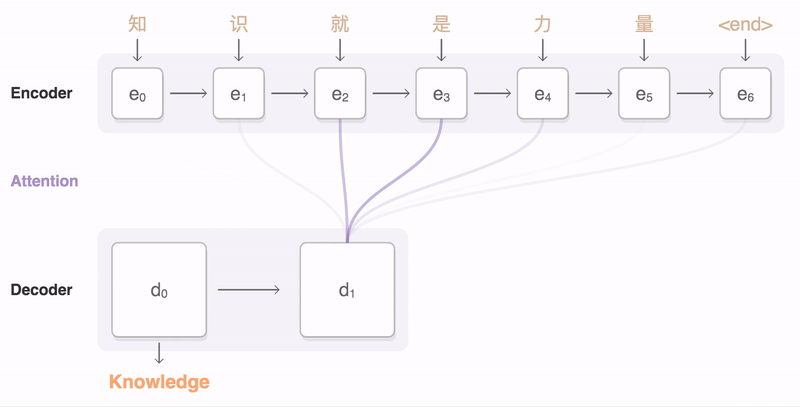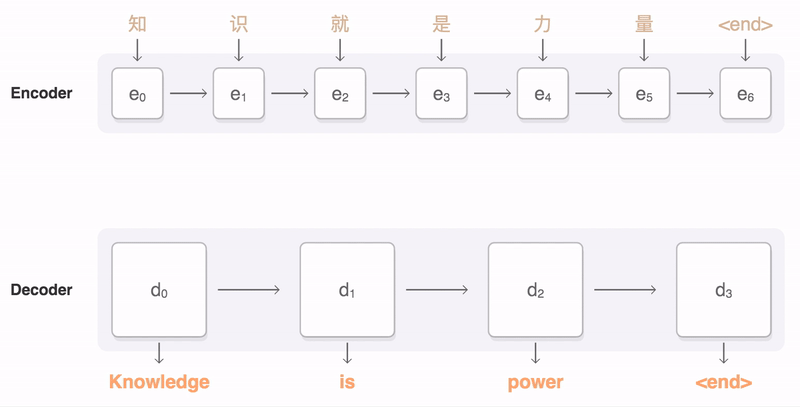
- 但这样每一步Decoder的输入都是原序列的一个"全局, 笼统的总结", 这是不太合理的: 在下图中, 在翻译"Knowledge"的的时候, 显然"力量"这个词是不太重要的.
 1
1- 在原始的Seq2Seq模型里面, 输入序列里面的所有元素都是同等重要的, 我们可以引入注意力机制来解决这一点.
- 在Seq2Seq里面引入注意力机制有不同的方法,下面要介绍的称为Bahdanau注意力
# 模型构建
我们将注意力模块整合到Decoder里面去, 这样只需要重写Decoder模块就好啦.
- 其实新增注意力模块也等价于采用新的context variable $\mathbf c$, 这个新的上下文变量会随着时间步的变化而变化.
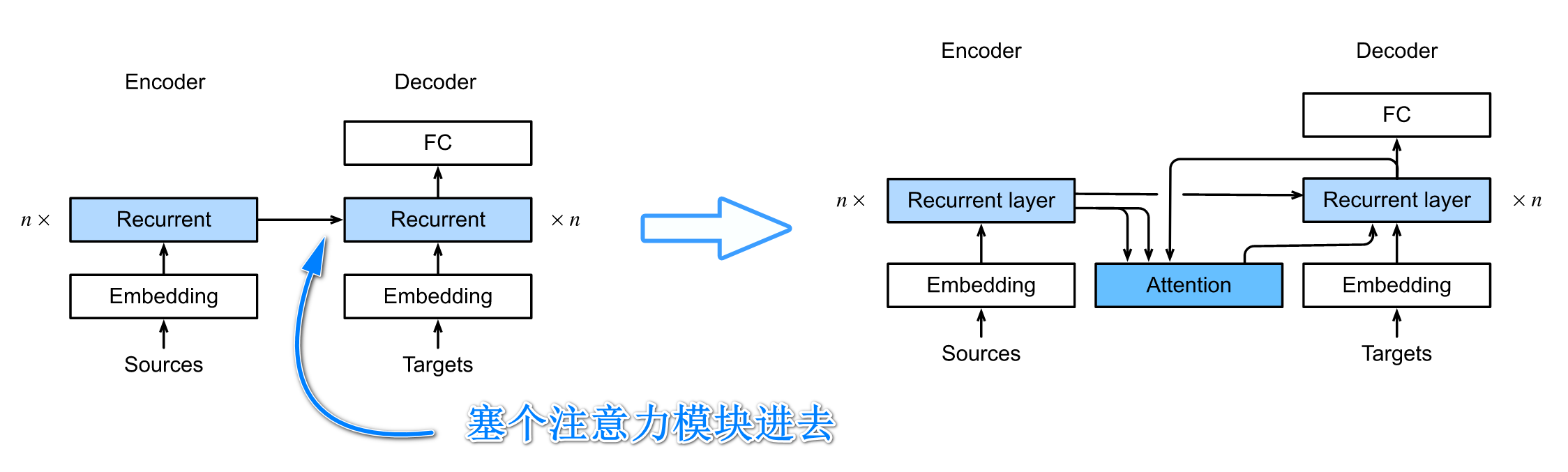
选择注意力评分函数
- 我们选择 Additive Attention, 因为加性注意力里面有可以学习的参数, 可以在一定程度上增加模型的表达能力.
Decoder隐状态的初始化
- 和之前一样, 我们使用Encoder最后一个时间步的
hidden_state来初始化decoder的hidden state
# 注意力模块
 假设输入序列长度为 $T$, 则Decoder在时间步 $t^\prime$ 的上下文变量 $\mathbf{c}{t’}$ 为: (这也是Attention Pooling在时间步 $t^\prime$ 的输出)
$$\mathbf{c}{t’} = \sum_{t=1}^T \alpha(\mathbf{s}_{t’ - 1}, \mathbf{h}_t) \mathbf{h}_t$$
其中:
假设输入序列长度为 $T$, 则Decoder在时间步 $t^\prime$ 的上下文变量 $\mathbf{c}{t’}$ 为: (这也是Attention Pooling在时间步 $t^\prime$ 的输出)
$$\mathbf{c}{t’} = \sum_{t=1}^T \alpha(\mathbf{s}_{t’ - 1}, \mathbf{h}_t) \mathbf{h}_t$$
其中:
- $\alpha$ 是Attention weight
- $\mathbf{s}_{t’ - 1}$ 是上一个时间步Decoder的hidden state, 对应Query
- $\mathbf{h}_t$ 是 Encoder
output里面第 $t$ 个时间步hidden state的输出. 既对应Key, 又对应 Value. - 需要注意的是每一个时间步 $t^\prime$ 的上下文变量 $\mathbf{c}_{t’}$ 是Encoder每一个时间步的Attention总和.
输入
- Query: $\mathbf{s}_{t’ - 1}$
- 来自Decoder循环层的
output
- 来自Decoder循环层的
- Key & Value: $\mathbf{h}_t$
- 来自Encoder的
output
- 来自Encoder的