D2L-71-Multi-Head_Attention
# 多头注意力
2022-04-27
Tags: #Attention #Multi-headAttention #DeepLearning
- 多头注意力就是对 Query, Key, Value 进行一些线性变换, 并行地计算多个注意力, 期望模型能学习到多样化的依赖关系.

- Another way of seeing it:
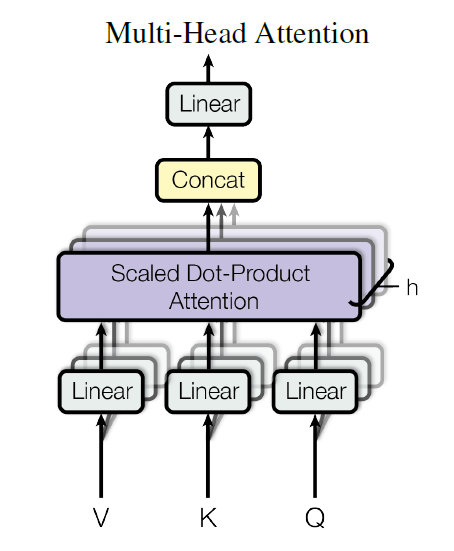 1
1
# 模型构建
下面我们给出 Multi-Head Attention 的形象化表示:
# Part 1
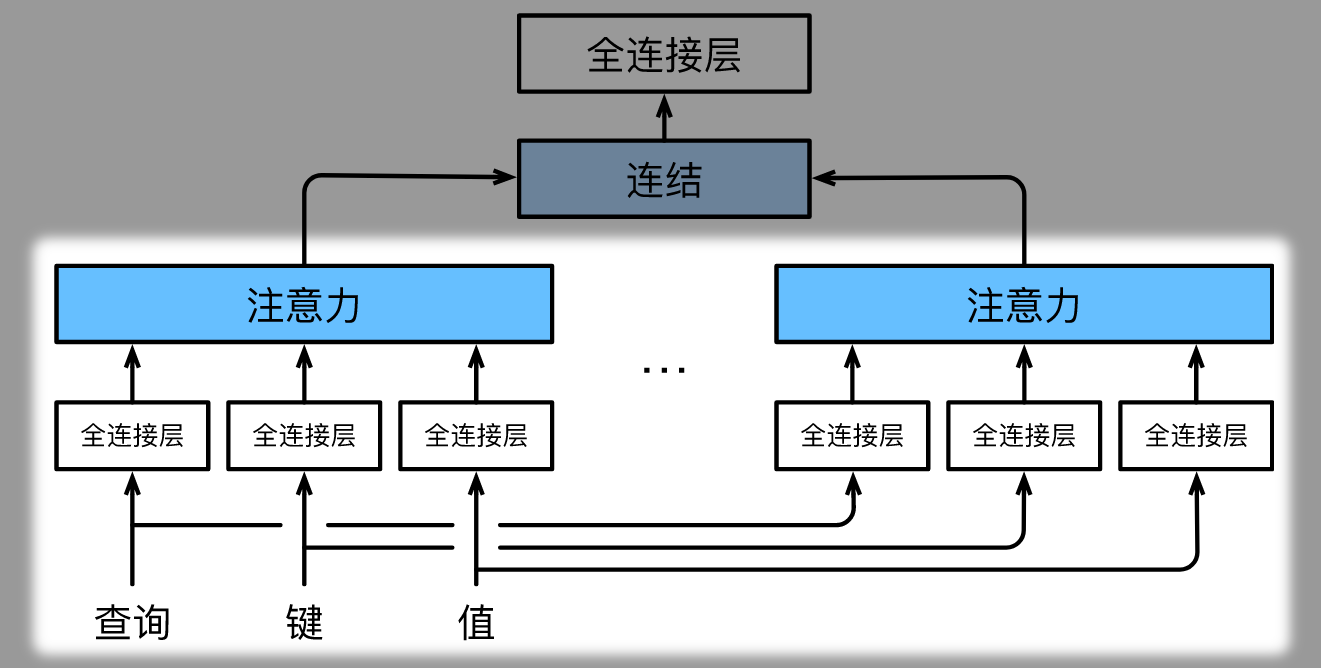
- 给定 Query $\mathbf{q} \in \mathbb{R}^{d_q}$、Key $\mathbf{k} \in \mathbb{R}^{d_k}$ 和 Value $\mathbf{v} \in \mathbb{R}^{d_v}$,则每个注意力头 $\mathbf{h}_i$($i = 1, \ldots, h$)的计算方法为:
$$\mathbf{h}_i = f(\mathbf W_i^{(q)}\mathbf q, \mathbf W_i^{(k)}\mathbf k,\mathbf W_i^{(v)}\mathbf v) \in \mathbb R^{p_v}$$
- 其中,可学习的参数包括
- $\mathbf W_i^{(q)}\in\mathbb R^{p_q\times d_q}$、 $\mathbf W_i^{(k)}\in\mathbb R^{p_k\times d_k}$ 和 $\mathbf W_i^{(v)}\in\mathbb R^{p_v\times d_v}$,
- 以及代表注意力汇聚的函数 $f$。$f$ 可以是 Attention Scoring Function 中的加性注意力或缩放点积注意力。
- 其中,可学习的参数包括
# Part 2
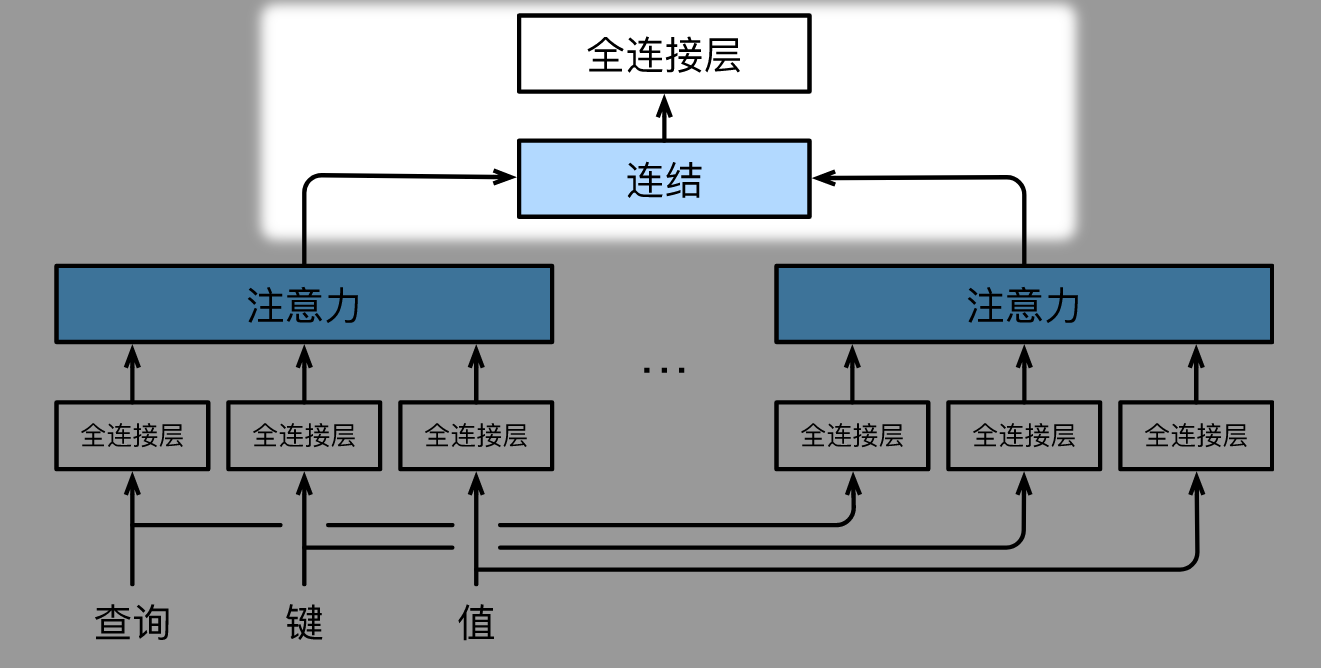
然后我们需要汇聚 $h$ 个注意力头的结果. 我们使用一个 FC 来进行汇聚 (也就是先进行 Concatenation, 再进行一个线性变换). $$\mathbf W_o \begin{bmatrix}\mathbf h_1\\vdots\\mathbf h_h\end{bmatrix} \in \mathbb{R}^{p_o}$$
- 其中可学习的参数为 $\mathbf W_o\in\mathbb R^{p_o\times h p_v}$
基于这种设计,每个头都可能会关注输入的不同部分,可以表示比简单加权平均值更复杂的函数。
# 模型实现
- 模型实现的关键在于: 并行地计算 $h$ 个头的注意力.
# Attention Pooling 参数规模的问题
- 首先, 因为多头注意力引入了大量的全连接层, 这会极大地增加 Attention Pooling 的参数大小和计算复杂度.
- 为了避免这个问题, 我们令 $p_q = p_k = p_v = p_o / h$, 也就是说, 现在每一个头里面的 Query, Key, Value 都只有原来的 $1/h$ 大.
- 因为 Value 大小变味了原来的 $1/h$, 所以 Attention 的输出长度也只有原来的 $1/h$. 而拼接以后的 $\begin{bmatrix}\mathbf h_1\\vdots\\mathbf h_h\end{bmatrix}$ 长度和原来一样.
- 最后的 $\mathbf W_o$ 输入输出大小一样.
| |
- 提问: 既然 Attention 前的线性映射缩小了 Query, Key 和 Value 的长度, 那为什么上面初始化时
key_size,query_size,value_size还是等于num_hiddens呢?- 其实 $W_q, W_k, W_v$ 表示的是将 $h$ 个小全连接层拼起来, 得到的一个"大号全连接层"的参数.

- 其实 $W_q, W_k, W_v$ 表示的是将 $h$ 个小全连接层拼起来, 得到的一个"大号全连接层"的参数.
# 并行化思路
为了实现并行计算, 我们先将线性映射之后的 Query, Key, Value 的按 $Batches\times heads$ 的方式拼接在一起:
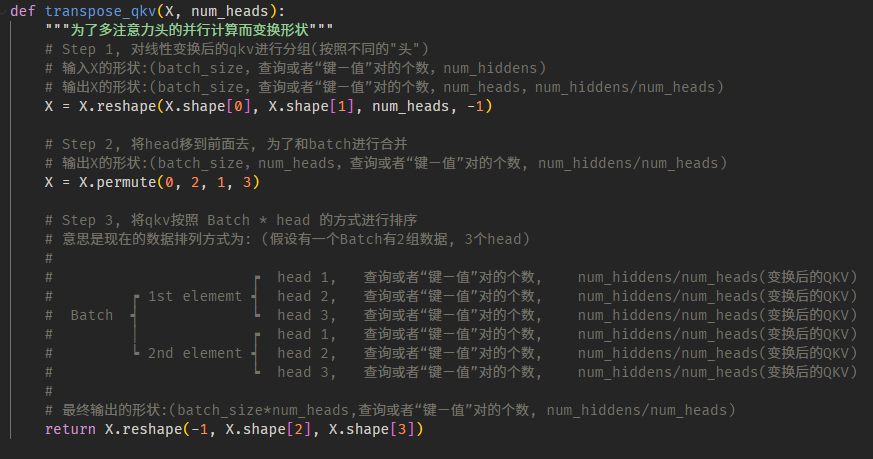
然后将拼接后的张量一起送进 Attention, 得到未融合的注意力输出,
再重新变换形状, 得到 $\begin{bmatrix}\mathbf h_1\\vdots\\mathbf h_h\end{bmatrix}$
最后再经过一个全连接层 $\mathbf W_o$, 得到融合后的注意力输出
| |
# 并行化细节
- 详细地说, 张量形状的变化如下图所示:

From Attention is All You Need ↩︎