D2L-72-Self-Attention
# 自注意力
2022-04-26
Tags: #Self-Attention #Attention #DeepLearning
- Attention 机制可以抽象为:1 $$\begin{align} \textit{Attention}(Q,K,V) = V\cdot\textit{softmax}\space (\textit{score}(Q, K)) \end{align}$$ 自注意力就是 $Q = K = V$ , 也就是同一个序列同时作为 Query, Key 和 Value.
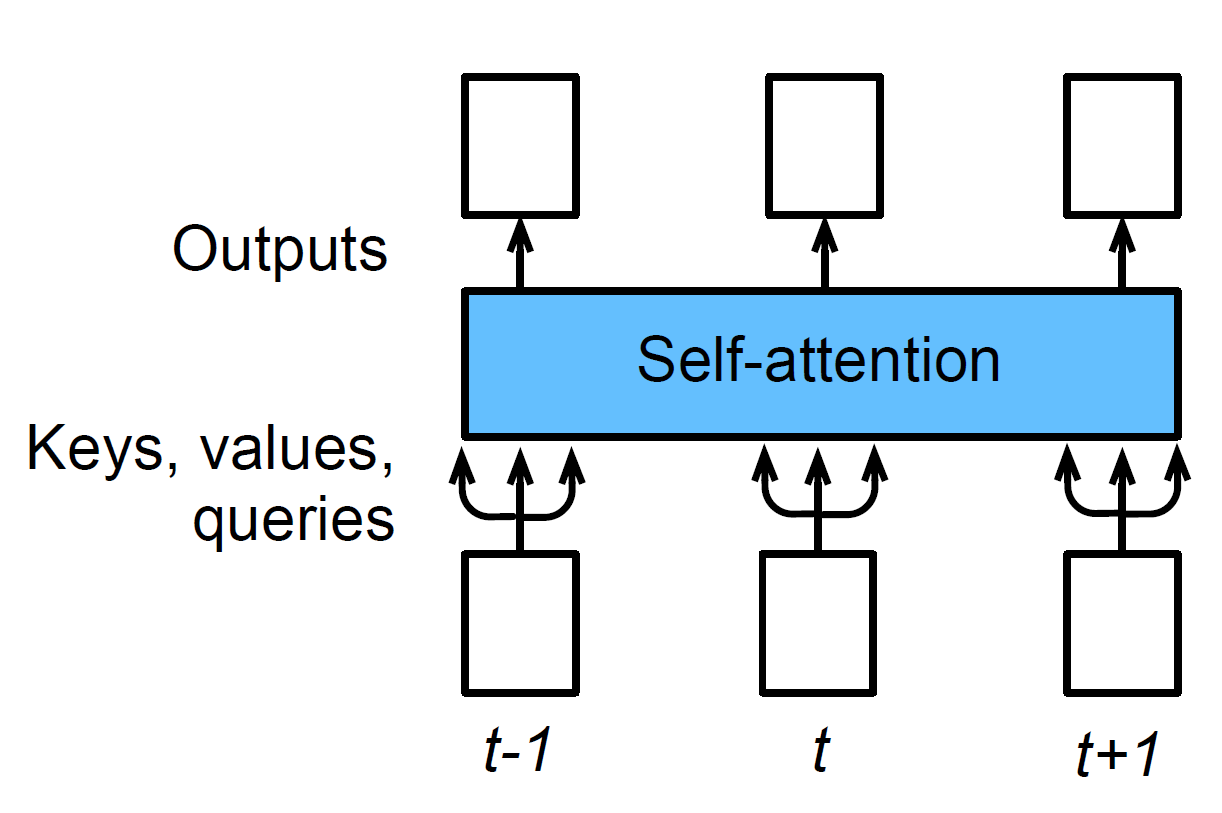
- 因为 Query, Key, Value 都是同一个序列 $X$, 所以自注意力的输出就是输入 $X$ 自身的一个加权平均, 只不过是一种具备 Attention 的, “动态的"加权平均.

# 实现
自注意力只是一种思想, 任何一种 Attention Mechanism 都可以通过把 $Q,K,V$ 变成一样的来实现自注意力.
下面是一个利用 Multihead Attention 来实现自注意力的例子:2
| |
# 优缺点
我们可以通过比较CNN, RNN, 自注意力三种结构, 来分析自注意力机制的优缺点:

$k$ : 卷积核大小
$n$ : 序列长度
$d$ : 输入和输出的通道数量, 隐状态数量, QKV 的长度
| CNN | RNN | 自注意力 | |
|---|---|---|---|
| 计算复杂度 | $\mathcal{O}(knd^2)$ | $\mathcal{O}(nd^2)$ | $\mathcal{O}(n^2d)$ |
| 并行度 | $\mathcal{O}(n)$ | $\mathcal{O}(1)$ | $\mathcal{O}(n)$ |
| 最长路径 | $\mathcal{O}(n/k)$ | $\mathcal{O}(n)$ | $\mathcal{O}(1)$ |
CNN 里面最长路径的意思是: 如果 $x_1$ 需要看到 $x_5$, 那么需要有 $n/k=5/3\rightarrow 2$ 个卷积层才能看到.
优点: 可以看到自注意力的并行度好, 最长路径短(信息流通容易) 适合用于处理长序列.
缺点: 但是自注意力的计算复杂度在序列较长的时候也增长的很快
总而言之,CNN 和自注意力都拥有并行计算的优势, 而且自注意力的最大路径长度最短。 但是因为其计算复杂度是关于序列长度的二次方,所以在很长的序列中计算会非常慢。
# 位置编码
- 在处理词元序列时,RNN是逐个的重复地处理词元的, 而自注意力则因为并行计算而放弃了顺序操作。 D2L-73-Positional_Encoding
回看我之前的笔记, 我当时记录的并没有这么清晰. 这说明在第一遍"学懂"以后, 第二遍的梳理往往能获得新的, 更凝练的理解. What is Attention, Self Attention, Multi-Head Attention? | Aditya Agrawal ↩︎