D2L-74-Transformer
# Transformer
Tags: #Transformer #Attention #DeepLearning
Transformer 是一个纯基于 Attention 的 Encoder Decoder 架构模型
Hugging Face Explorable Transformer: exBERT
# Motivation
- 我们在 Self-Attention 中比较了卷积神经网络(CNN)、循环神经网络(RNN)和自注意力(self-attention)。值得注意的是,自注意力同时具有并行计算和最短的最大路径长度这两个优势。因此,使用自注意力来设计深度架构是很有吸引力的.2
# 整体架构
- 其实整个 Transformer 的结构是很清晰的:总的来说,Transformer 分为 Encoder 和 Decoder 两个部分,并且每个部分都由 $n$ 个块构成。
# Encoder Block
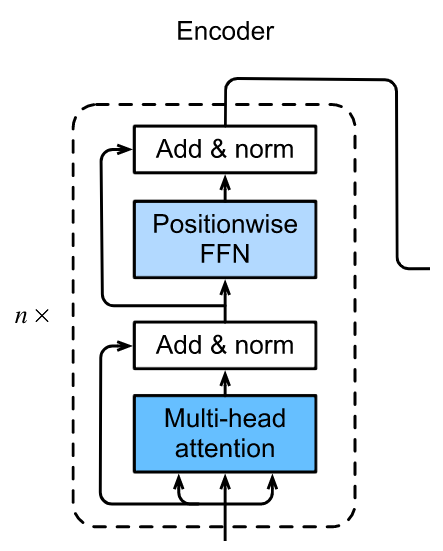
每个 Encoder 块里面包含一个注意力层和一个 FFN 层(其实就是两层全连接)
- Attention 层使用多头自注意力, 用来从整个输入序列里面提炼信息
- FFN层对每一个Position进行相同的变换
在每一次变换以后, 都进行一次Layer Norm和残差连接
# Decoder Block
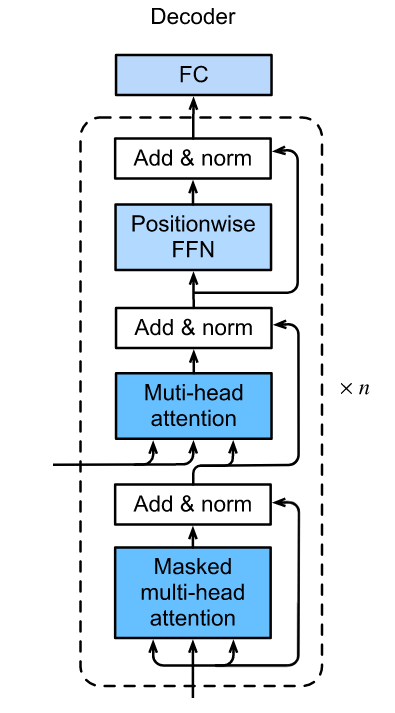
每个 Decoder 块里面包含 2 个注意力层和 1 个 FFN 层
- 第一个注意力层也使用多头自注意力, 但是由于预测是逐步完成的, 所以需要Mask掉未知的项
- 第二个注意力接受 Encoder 的输出, 使用多头注意力, 接收上一层的输出作为 Query.
- 最后一层使用 FFN 对每一个 Position 进行单独变换.
和 Encoder Block 一样 , 每一层后面都跟着一次 Layer Norm 和 一次残差连接.
下面我们详细的介绍每一个 Building Block:
# Attention: 3 different kinds
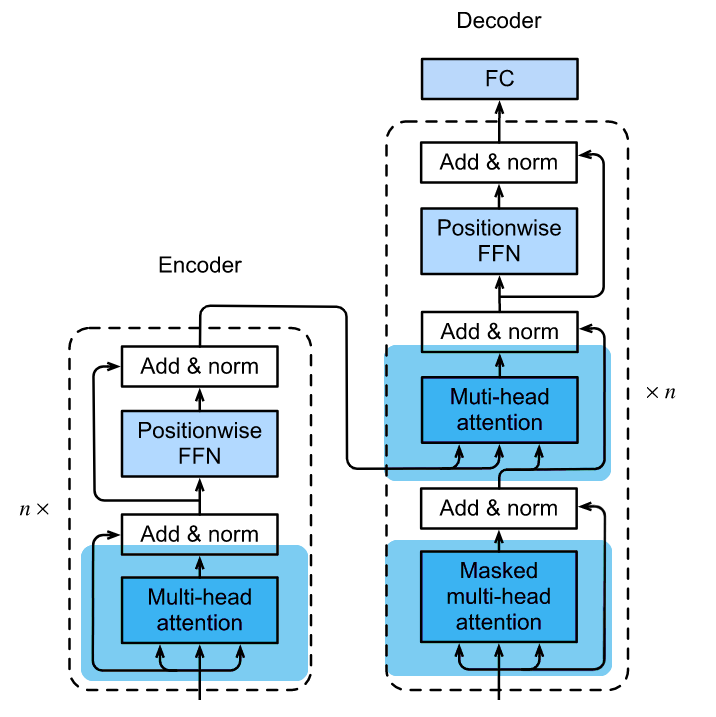
在 Transformer 里面, 三个注意力层有着细微的差别:
Encoder 里面的注意力层: 多头自注意力
- 并行地提取输出序列里面的信息
Decoder 里面的注意力层 A: Mask 后的多头自注意力
- 因为预测是一步一步地进行的, 我们不能参考当前时间步以后的序列. 所以需要进行 Mask.
- 但是它仍然是自注意力, 只不过每一次自注意力能使用的长度都在增加.
Decoder 里面的注意力层 B: 常规的多头注意力
- 这一层接收 Encoder 的输出作为 Key-Value Pair, 而 Query 是上一层的输出. 所以它不属于自注意力了.
可以看到所有的Attention层都使用了 多头注意力, 并且我们在能使用自注意力的地方都使用了自注意力, 与构建整个网络的Motivation相一致.
# Position-wise Feed-Forward Networks
- Position-wise FFN 就是一个两层的 MLP.
- 之所以称它为"Position-wise" FFN, 是因为它只对输入的最后一个维度进行变换(
num_hiddens, 每一个样本的特征维度). 也就是说它只在每一个样本内部进行特征转换, 不同位置的样本不会相互影响.
| |
- 在 Transformer 里面, Position-wise FFN 通常先将特征维放大, 然后再转换回去:
| |
原论文的说明


# Add & Norm
- 我们之所以将这两个步骤抽象为一个组件, 是因为它们都是构建有效的深度架构的关键。
# Residual Connection
- 残差连接的思想来自于 ResNet, 它在保证网络的性能的同时使训练更加容易了.
- 但是残差连接需要两个输入的形状相同, 这就要求 Attention Layer, FFN 都不能改变张量的形状.
# Layer Norm
我们之前学习过 Batch_Normalization-批量归一化 可以用来加速收敛, 我们自然也想把它用在 Transformer 里面.
但是 Transformer 的输入是长度变化的序列: 不仅训练网络的时候长度是变化的, 预测的时候长度更是不确定的, 这会给 Batch Normalization 带来一些问题:
- Batch Norm是按feature来进行归一化的, 也就是说, 它会将一个Batch里面的所有Sequence的同一个Feature抽出来进行归一化.
- 但因为序列长度是变化的, 分配给每一个Sequence的"份额", 会受其他Sequence的影响: 要是有一个Sequence很短, 而其他Sequence都很长, 那么短的Sequence所有Features都会比较小, 这是不太合理的,如下图所示:

而Layer Norm只对一个"Layer"里面的一个样本的进行归一化, 不同长度的样本之间不会相互影响.
讲解见视频
25:38Transformer论文逐段精读总之, 尽管Batch Norm在计算机视觉中被广泛应用,但在自然语言处理任务中(输入通常是变长序列)Batch Norm通常不如Layer Norm的效果好。3
# 实现
- 值得注意的是, 我们还在最后进行了 Dropout
| |
# Input Preprocessing: Positional Encoding & Embedding
对于输入我们需要做两件事:
- 首先需要把序列转化为向量: Embedding
- 然后因为
自注意力忽略了原始序列的位置信息, 我们需要再把位置信息加回去: Positional Encoding
- 在Positional Encoding里面还加入了Dropout
# 实现
- 因为利用三角函数实现的位置编码输出范围在-1 和 1 之间, 为了平衡 Positional Encoding 和 Embedding 的数量级, 我们需要先将 embedding 的结构乘上 $\sqrt{d}$, 其中 $d$ 是 embedding 的维数.
| |
- 注意 Positional Encoding & Embedding 在 Encoder 和 Decoder 里面都是有的。
# Putting it all together
- 有了所有的 Building Blocks 之后, 我们便可以构建起整个 Transformer 模型了:
- 下面的视频形象而直观的展现了 Transformer 模型的工作过程:
More illustrations:4
![]()
![]()
- 下面这个笔记本里面有一个很好的多头注意力可视化:
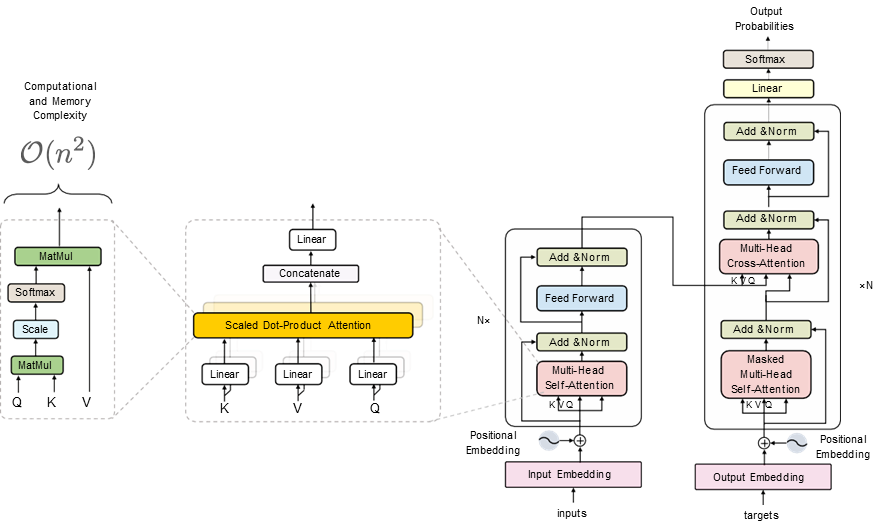
# Further Development
- 尽管 Transformer 架构是为了“序列到序列”的学习而提出的,但在后续基于 Transformer 的模型中(比如 BERT),Transformer Encoder 或 Transformer Decoder 通常被单独用于不同的深度学习任务中。