D2L-75-BERT
# Bidirectional Encoder Representations from Transformers (BERT)
Tags: #BERT #Transformer #DeepLearning

# Motivation
# 构建一个通用的语言模型
- 在计算机视觉领域中, 我们能对一个已经训练好的大型网络进行微调(Fine-tune), 以较小的计算成本和网络改动就能获得很好的模型.
- BERT就是期望能够构建一个足够强大的预训练模型(Pretrained), 来适配各种各样的任务.
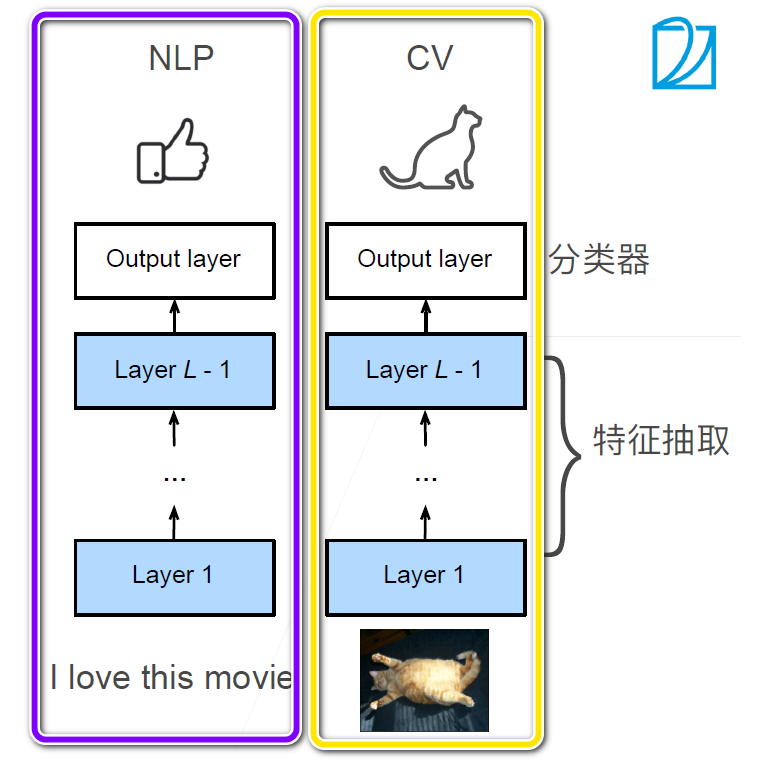
# 结合两个现有架构的优点: ELMo & GPT
# GPT: task-agnostic
其实在 BERT 以前, OpenAI 已经提出了 GPT (Generative Pre-Training,生成式预训练)模型, 试图提供一种既考虑上下文语意(context-sensitive), 又能适配多任务(task-agnostic1)的模型
但是 GPT 是基于 Transformer Decoder 的, 这就意味着它具备自回归模型(Auto-regressive)的性质: 只能"向前看"(从左到右).
在 Fine-tune 的时候, GPT 不冻结任何参数, 所有原来的所有参数会跟着新的输出层一起训练
# ELMo: Bi-directional
尽管基于 BiLSTM 的 ELMo 模型能够很好的综合两个方向的语义信息, 但是 ELMo 是 task-specific 的, 无法适配多种任务.
这就意味着我们 Pretrained ELMo 之后, 还需要为不同的 NLP 任务设计不同的后续架构, 这是很累的
# BERT: Combining the Best of Both Worlds
- BERT 基于 Transformer 的 Bidirectional Encoder, 既可以综合 Bidirectional 的上下文信息, 又可以适配多种模型(task-agnostic).

- 并且 BERT 在 Fine-tune 的时候和 GPT 类似: 所有原来的所有参数会跟着新的输出层一起训练.

# Model - Overview
作为一个预训练模型, 训练 BERT 分为 Pre-train 和 Fine-tune 两部分.
- 而且我们需要为 Pretrain 设计一个通用的训练任务, 适配多种应用场景.
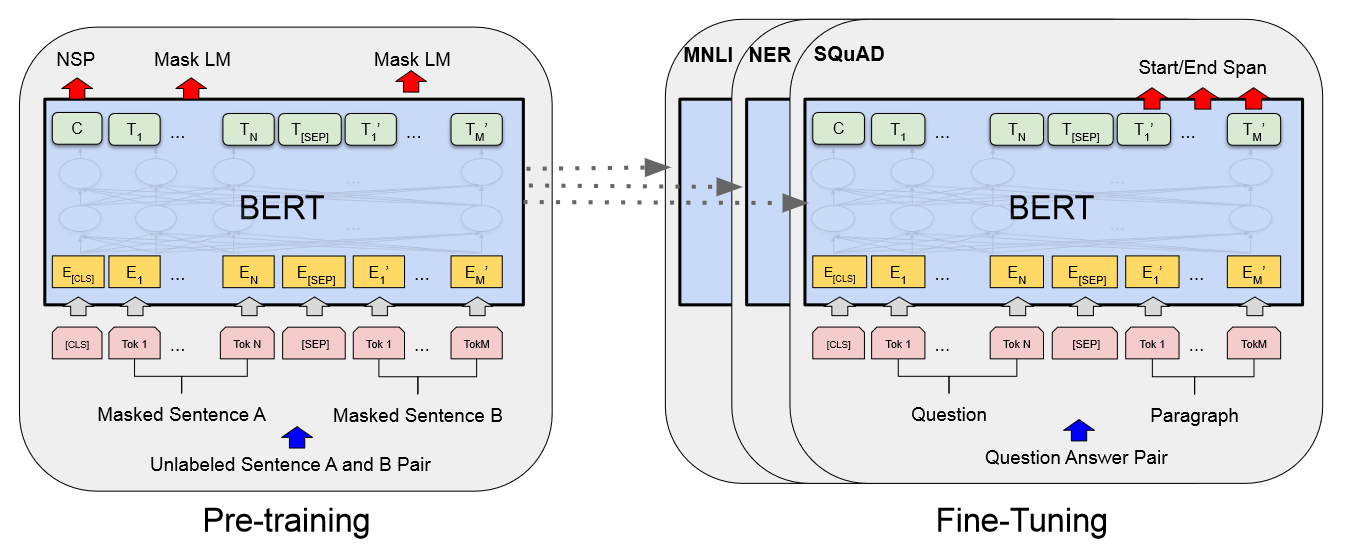
- 而且我们需要为 Pretrain 设计一个通用的训练任务, 适配多种应用场景.
BERT 相当于一个只有 Encoder 的 Transformer.
- 为了适配设计的"通用任务", 我们还需要对模型进行相应的改进 ,后面详述.
作为预训练模型, BERT提供了不同规格的两个版本.
| |
# 预训练任务
# Model - Detail
# Masked Language Model 任务
- 我们使用一个单隐层的 MLP 来将 Encoder 的输出转化为预测的单词标签(Vocab 里面的序号)
| |
# Next Sentence Prediction 任务
- 我们依然使用一个单隐层的 MLP 来处理 NSP 任务
- 但是和 MLM 任务不同, BERT 在这一步只使用了每一个序列的
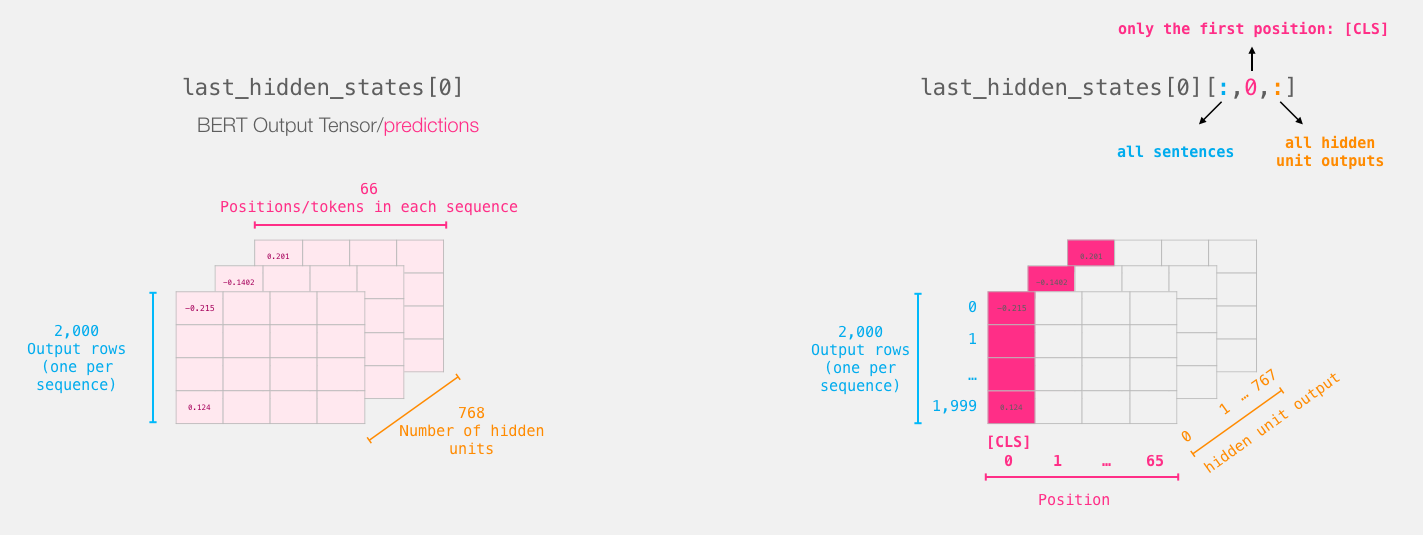
<cls>标签, 这个标签在每个句子的开头, 可以使用encoded_X[:, 0, :]来提取出来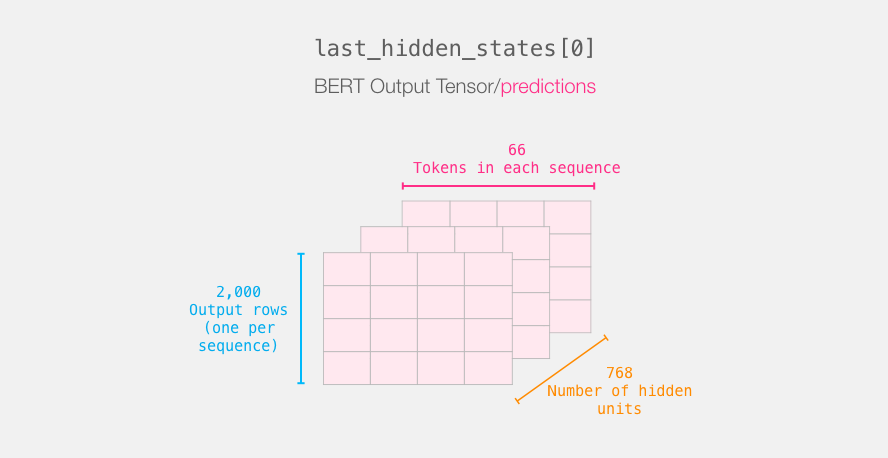
 2
2 <cls>标签表示 Classification, 是 BERT 中专门用于句子分类的一个标签.
| |
# 完整的模型
| |
# Fine-tune

Agonistic: someone who does not know, or believes that it is impossible to know, if a god exists 不可知论者(对神存在与否不能肯定或认为不可知), ↩︎
A Visual Guide to Using BERT for the First Time – Jay Alammar – Visualizing machine learning one concept at a time. ↩︎