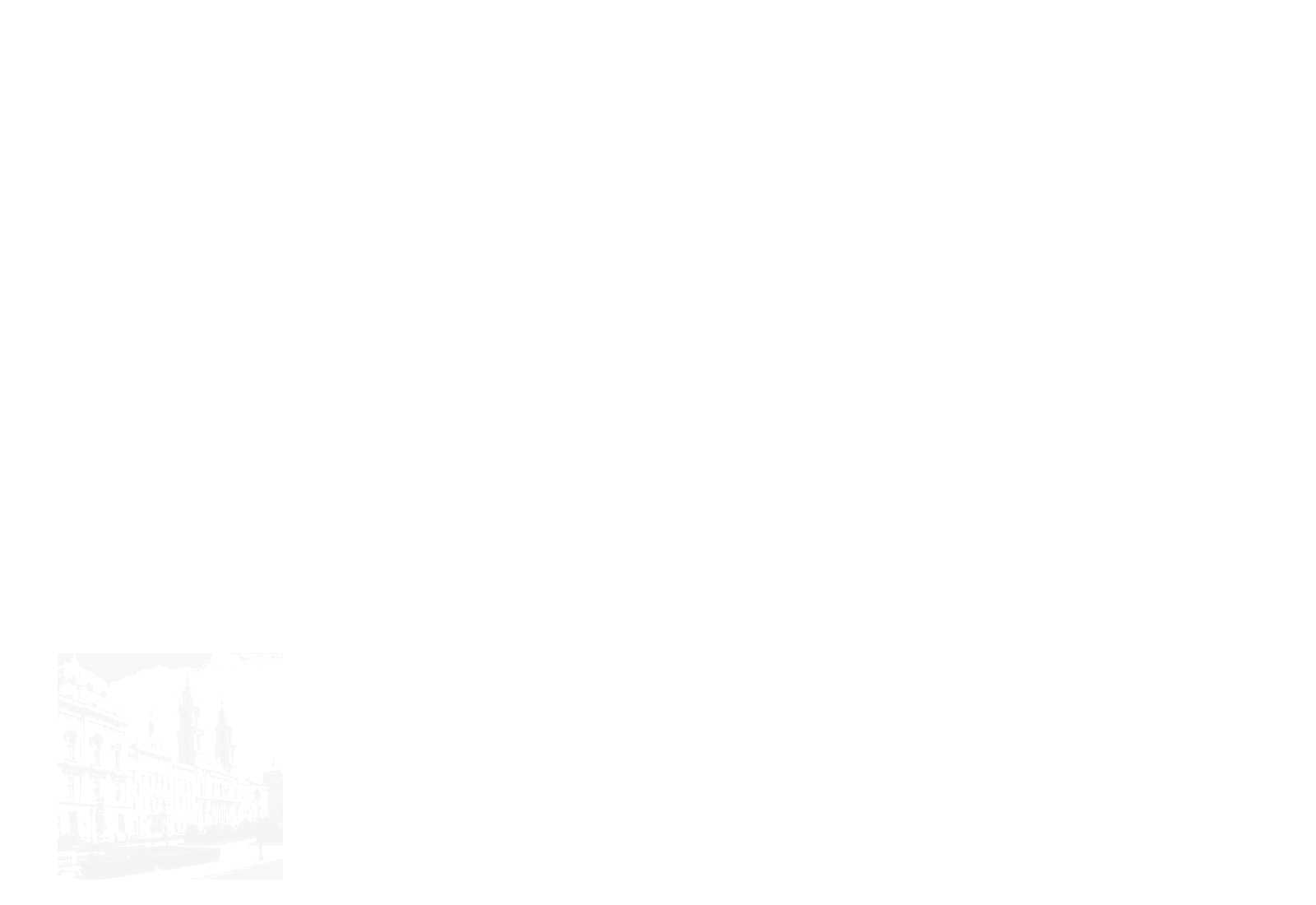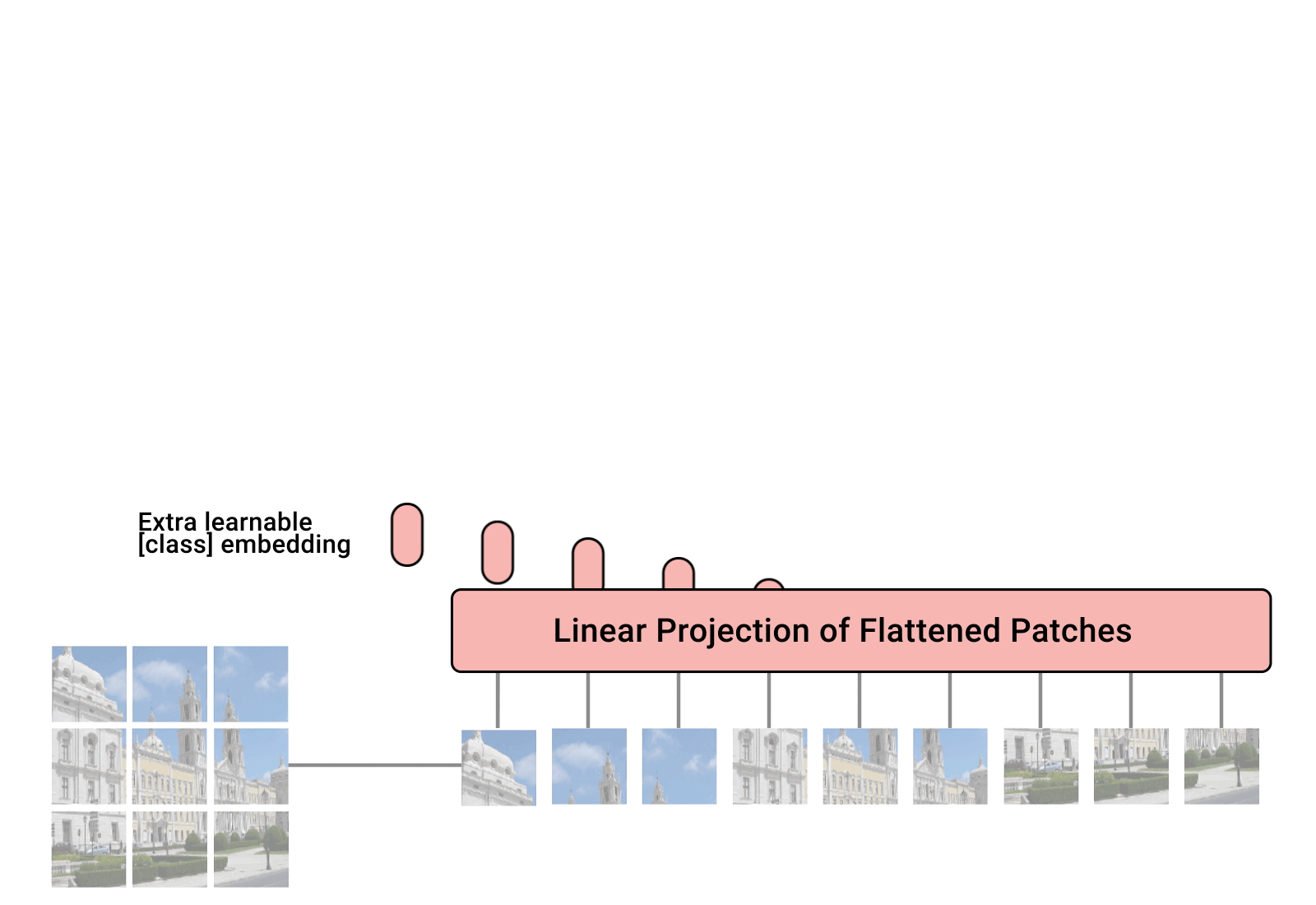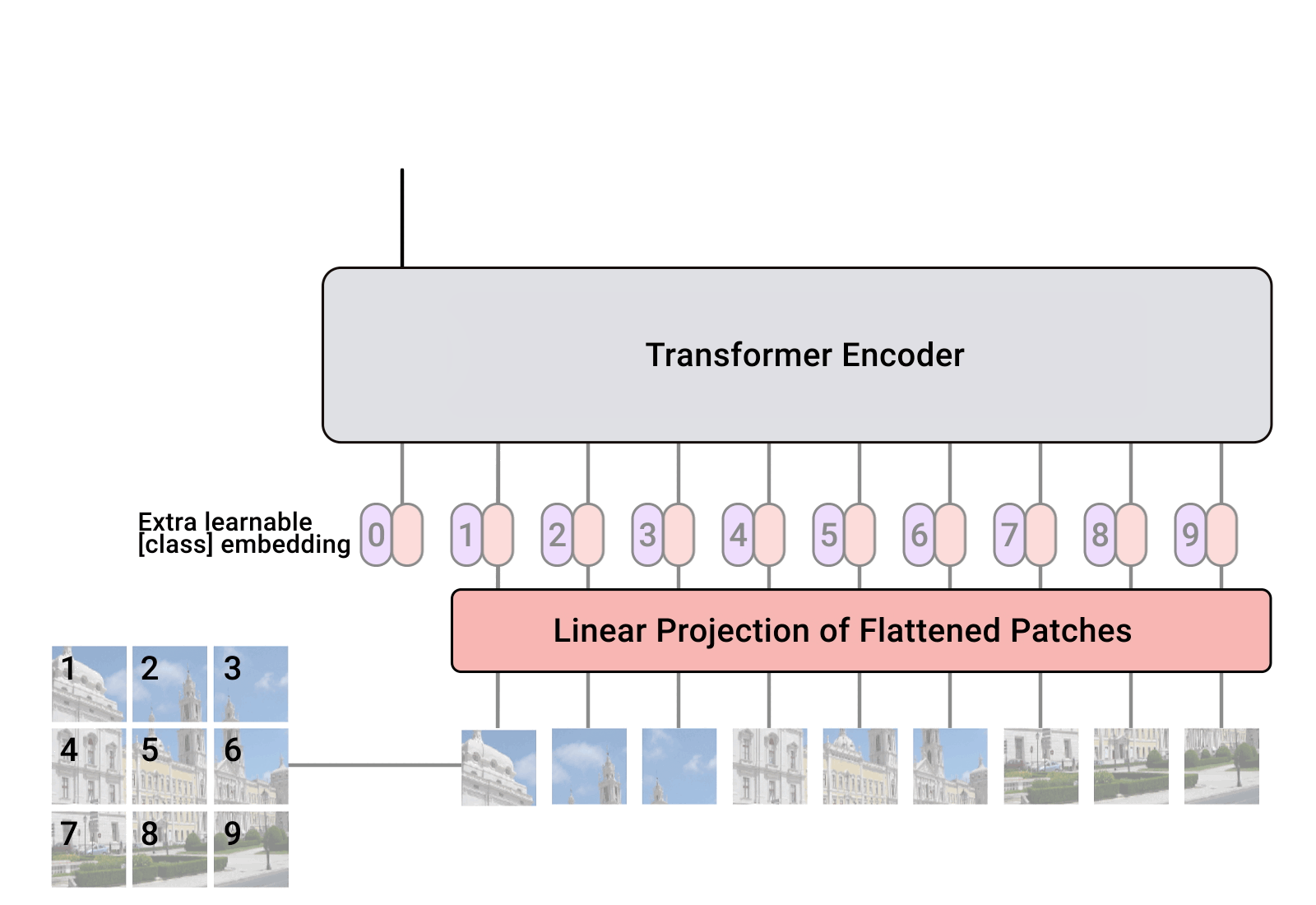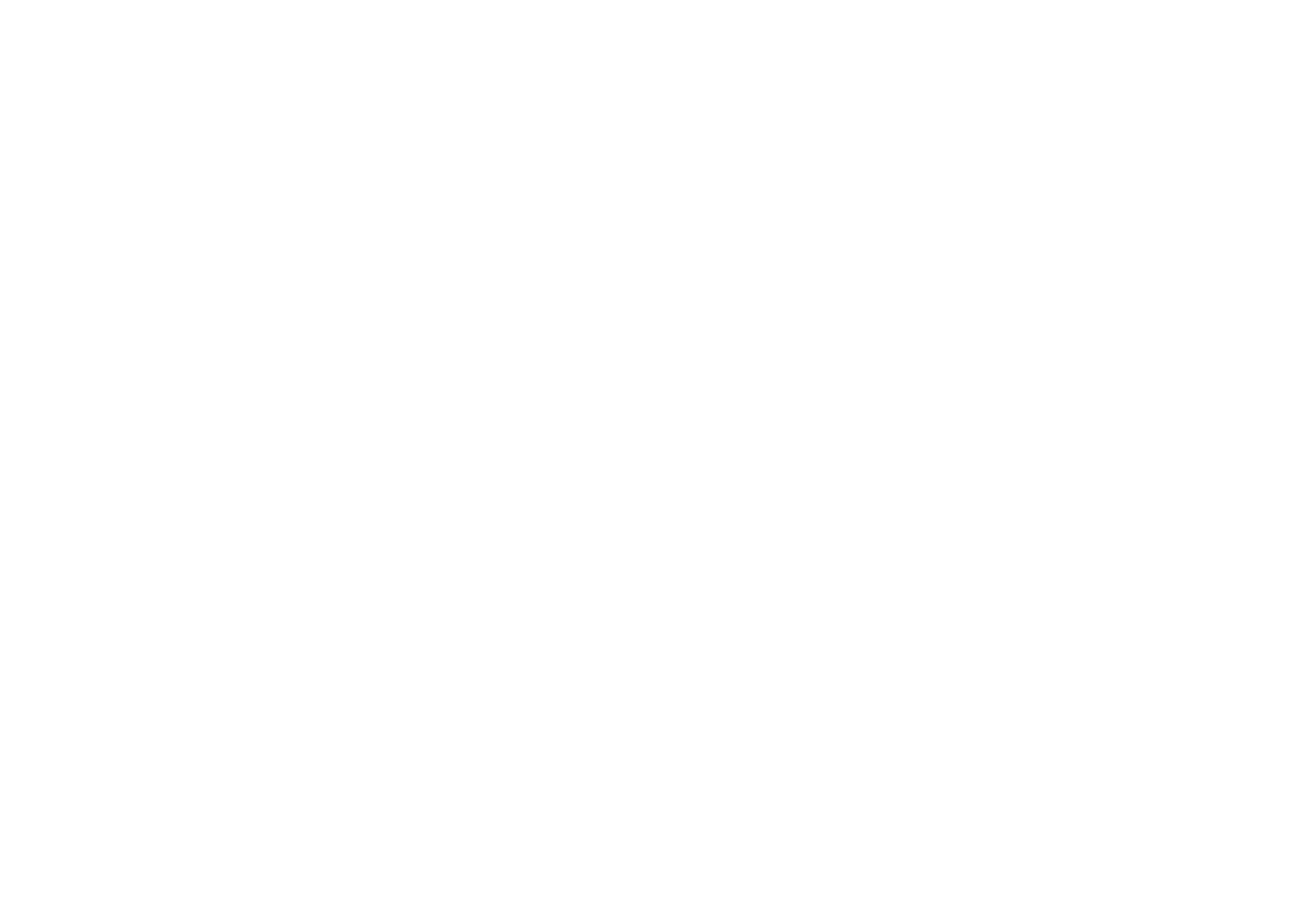Vision Transformer (ViT)
# Vision Transformer
2022-09-22
Tags: #ViT
# How the Vision Transformer works in a nutshell1
The total architecture is called Vision Transformer (ViT in short). Let’s examine it step by step.
- Split an image into patches
- Flatten the patches
- Produce lower-dimensional linear embeddings from the flattened patches
- Add positional embeddings
- Feed the sequence as an input to a standard transformer encoder
- Pretrain the model with image labels (fully supervised on a huge dataset)
- Finetune on the downstream dataset for image classification